As a developer, maintaining a high work productivity is crucial. However, transcribing scanned documents, mockup images, or text infographics slows down the process.
Having some experience in developing myself, I understand how irritating it can be when you have to manually transcribe something. But you can remove this irritation by leveraging image-to-text conversion tools.
These tools can save you time by accurately extracting the text, helping you maintain productivity. However, it is challenging to sift through the myriad of tools available to find the right one that caters to our needs. Hence in this blog post, I am going to bring down the top image-to-text conversion tools.
Shape the Future of Tech! Join the Developer Nation Panel to share your insights, drive tech innovation, and win exciting prizes. Sign up, take surveys, and connect with a global community shaping tomorrow’s technology. Join now.
These tools will smartly streamline your workflow so you do not need to worry about manual transcribing.
Top 4 Image-to-Text Conversion Tools
Below I am going to tell you about the top 4 image-to-text tools that can ease the workflow for you as a developer.
1. Imagetotext.info
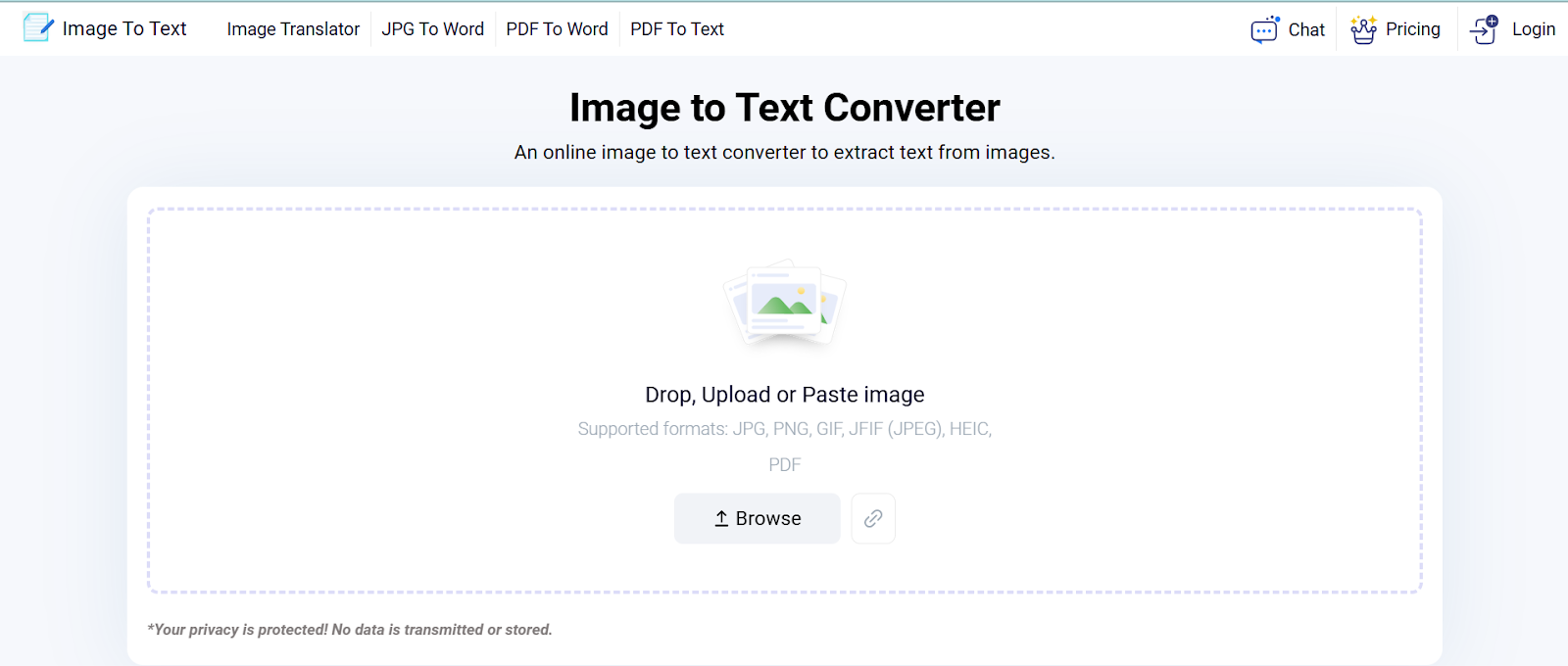
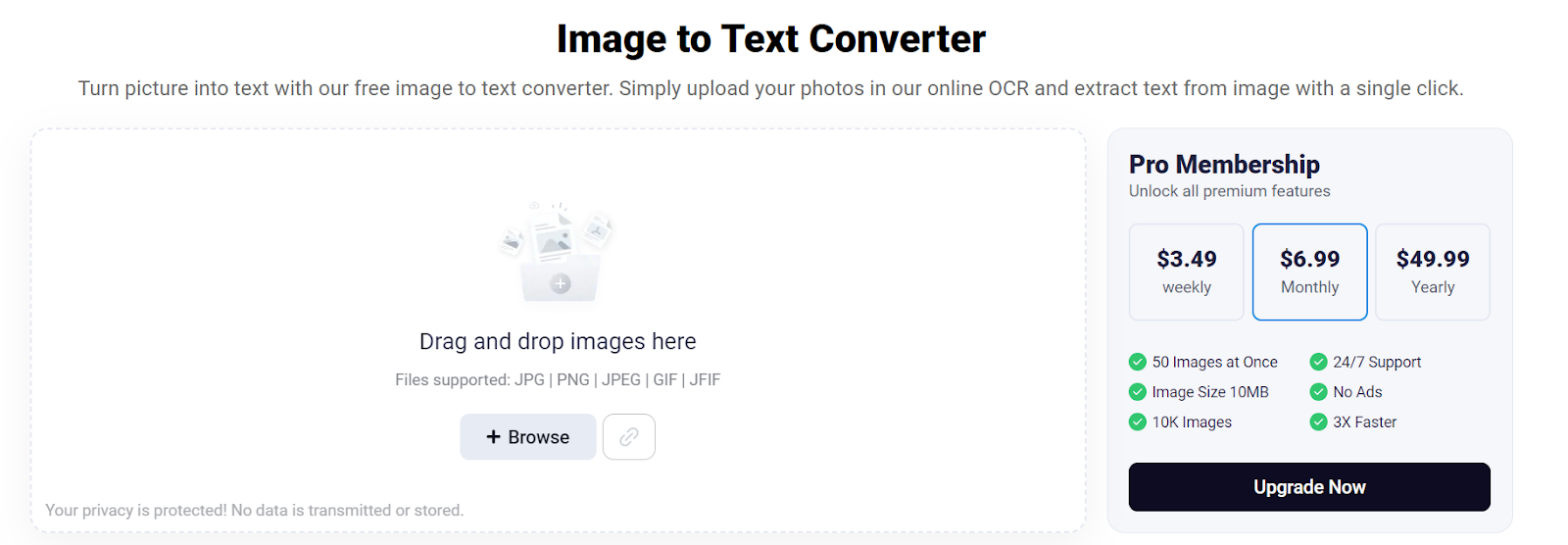
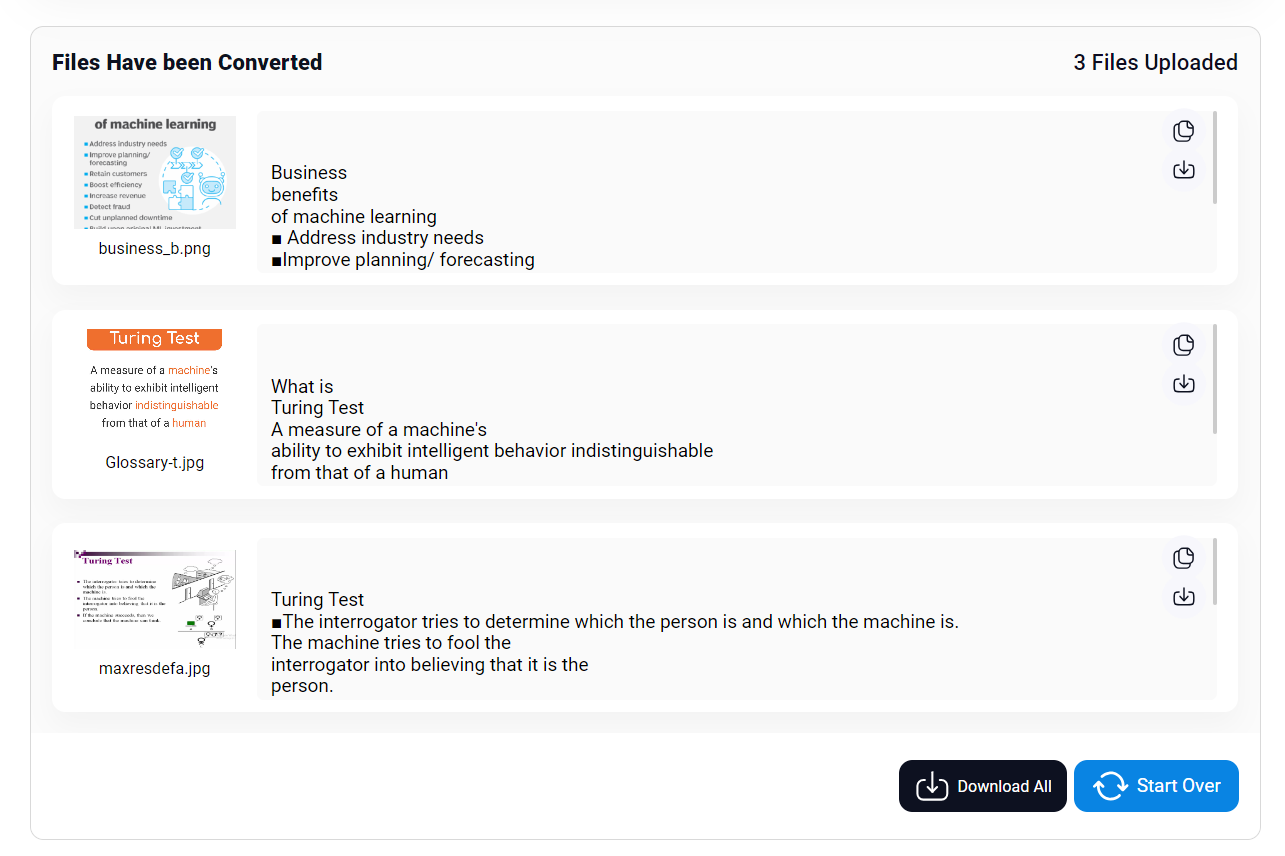
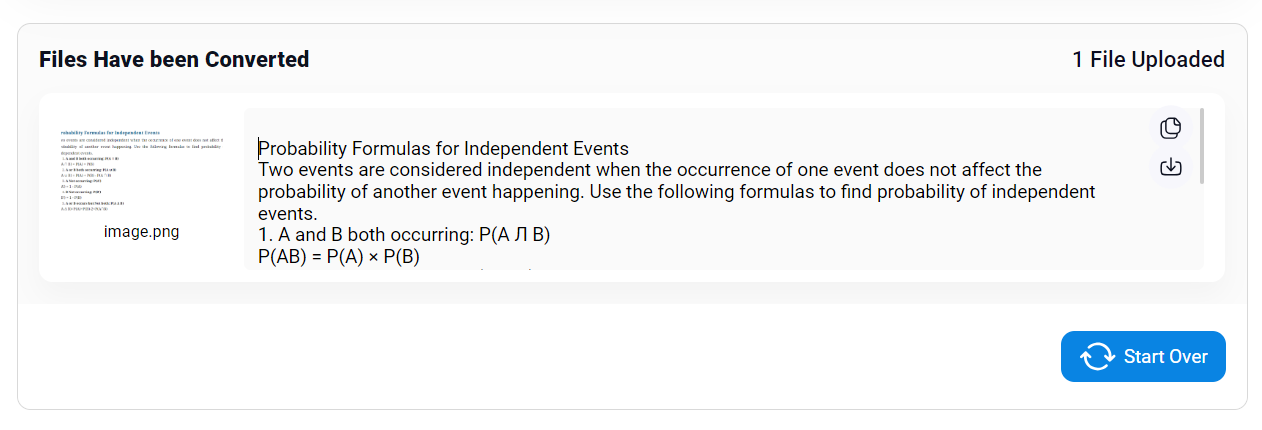
The first one on my list is Imagetotext.info. The tool is based on advanced open-source Tesseract OCR software and performs AI-based text extraction from images.
Before features, let me tell you why I consider this tool as the best option.
The first reason is that we can use it for free without any limited attempts. Second, I found its image processing speed faster than others.
Third, its availability as a mobile app, web app, and desktop app makes it a more compatible option.
Key Features:
Imagetotext.info boasts the following features:
- Processes image files in multiple formats
- Allows processing images that are available online
- Offers multilingual support
- Integrated with 12 other tools
- OCR-based extraction brings high accuracy in output
- Can process a batch of images in one go
Pricing:
As I have told you, the Imagetotext.io is free to use (unlimited). But its free version only accepts 3 images at a time. To process a bigger number of images, you have to opt for a premium plan. Currently, it is offering 3 premium plans that are priced as follows:
- $2.5 Weekly
- $5 Monthly
- $49.88 Yearly
2. Ocr.best
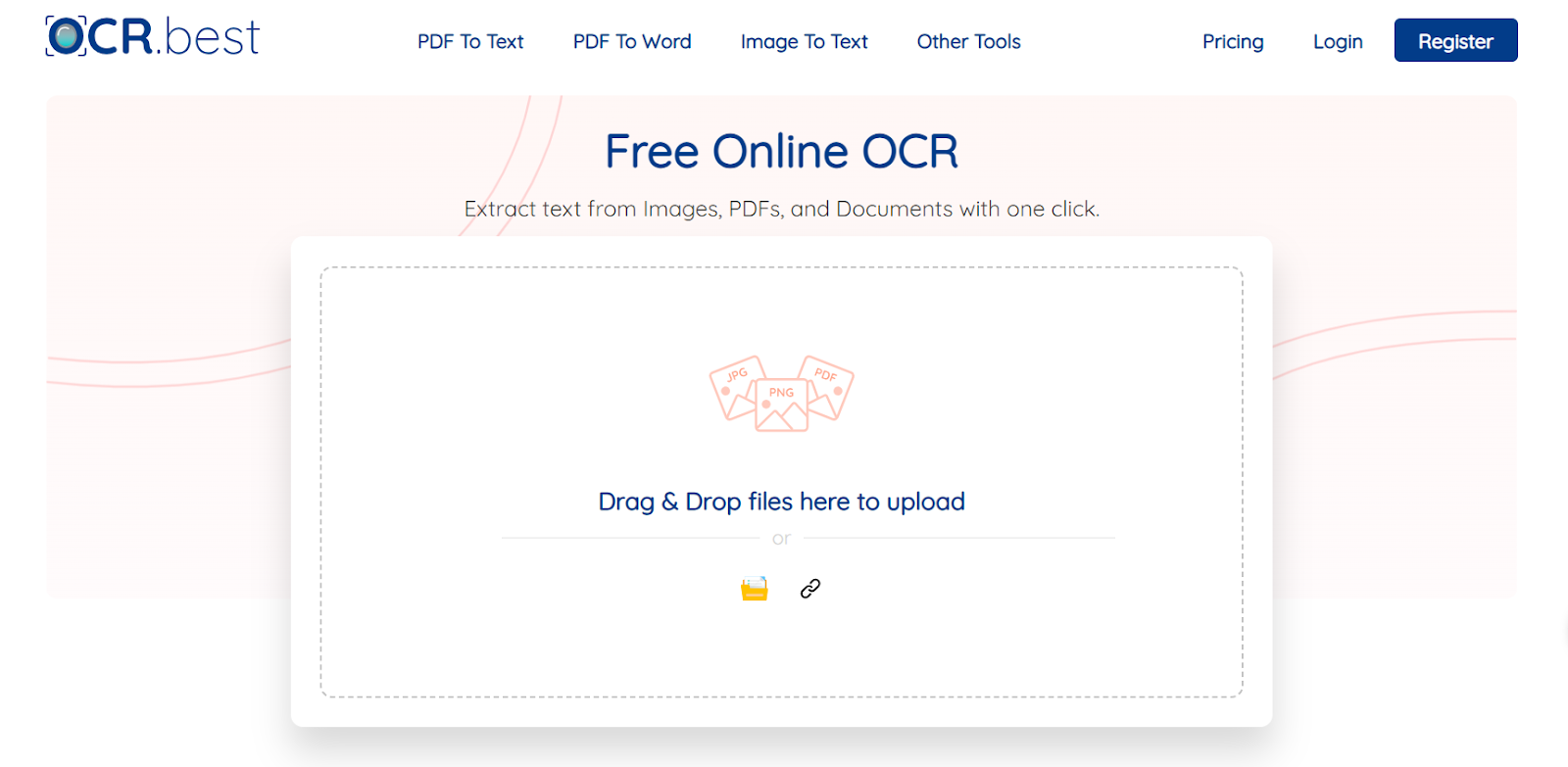
The second-best image-to-text converter on my list is Ocr.best. As the name suggests, it also uses optical recognition technology paired with machine learning.
This tool is very similar in most of the features to the previous one and can even detect mathematical syntax that’s present in images and scanned docs.
And as a developer, you already will be aware of the importance of mathematical syntax.
Key Features:
Ocr.best brings the following set of features to users:
- Supports image files in various formats, including PDFs
- Available in multiple languages for wider accessibility
- Allows processing of images directly from online sources
- App available for Android and iOS
- Handles more than one image in one go
Pricing:
Like Imagetotext.info the free version of this tool also allows you to submit 3 different images (up to 10 MB in size) at a time. But by having a premium subscription you can process up to 50 images in one go. The pricing is almost the same as the previous one but there’s just a slight difference.
- $2.49 Weekly
- $4.99 Monthly
- $49.88 Yearly
3. Prepostseo Image to Text Converter
Image-to-text converter by Prepostseo is another top choice when it comes to converting images into text. The platform is known for providing free access to a variety of tools.
The reason I consider it among the top options is that it can handle large-size image files (up to 20MB). This limit is double the number of the previous two.
But here a question arises in mind. If its limit is higher than others, why have I kept this tool at third position? Well, that’s because it doesn’t support PDF files. This means you cannot extract text from images available as a PDF file using this tool.
Key Features:
The Image to Text Converter by Prepostseo has the following features:
- Come with a good UI/UX that makes it simple to use
- Offers good compatibility both on phone and desktop devices
- Allows processing online images by link submission
- Provides downloading the output text in two formats i.e., TXT and Word document
- Detects mathematical syntax and handwritten texts
Pricing:
The pricing of this tool is higher than the other. But when you look at its features like the accurate output organized in a Word document and the large image file size limit, it seems to be justifiable. Plus, another notable thing is that the premium plan doubles the submission limit further to 20MB files at a time.
The image-to-text converter by Prepostseo doesn’t offer a weekly plan but has a monthly and yearly plan.
- $10 Monthly
- $75 Yearly
4. Google Lens
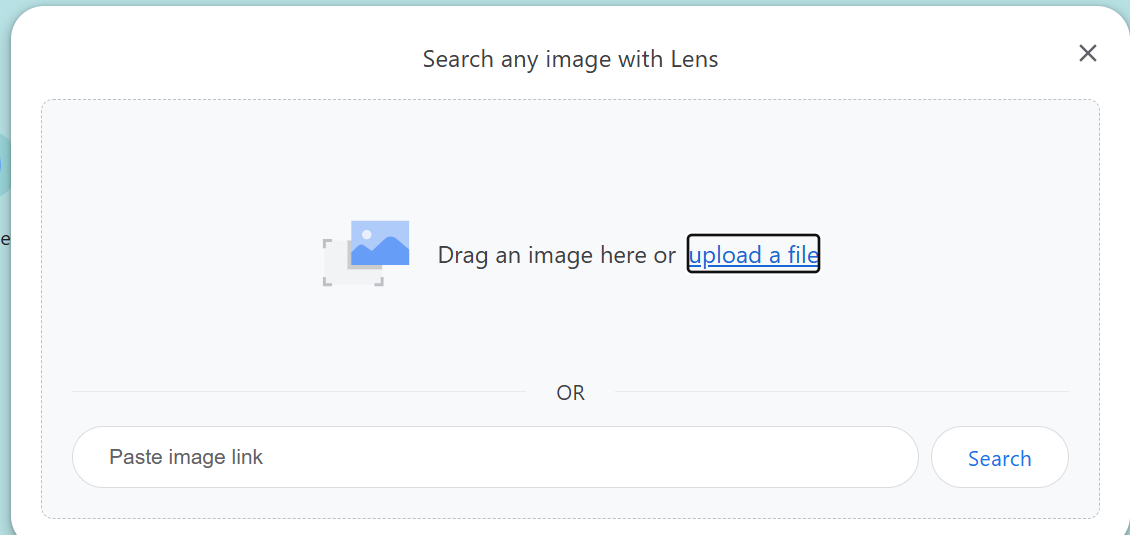
This tool by Google also performs the extraction of text from images. However, there are many limitations. For example:
- You can submit only one image at a time
- It doesn’t provide text as a file in any format, you can only copy the text, not download it
- Process is a bit lengthy
Key Features:
Google Lens offers the following features to users:
- Free to use
- Available as a mobile app and in the browser
- Can take you to the image source
- Works without internet for certain languages
- Translates extracted text into numerous languages on the spot
Takeaway
As developers, time is a luxury for us and we cannot afford to lose it. Whenever there comes a need to extract text from images the 4 tools that I have discussed above can be reliable solutions. By integrating them into your workflow, you’ll not only streamline your tasks but also maintain productivity.