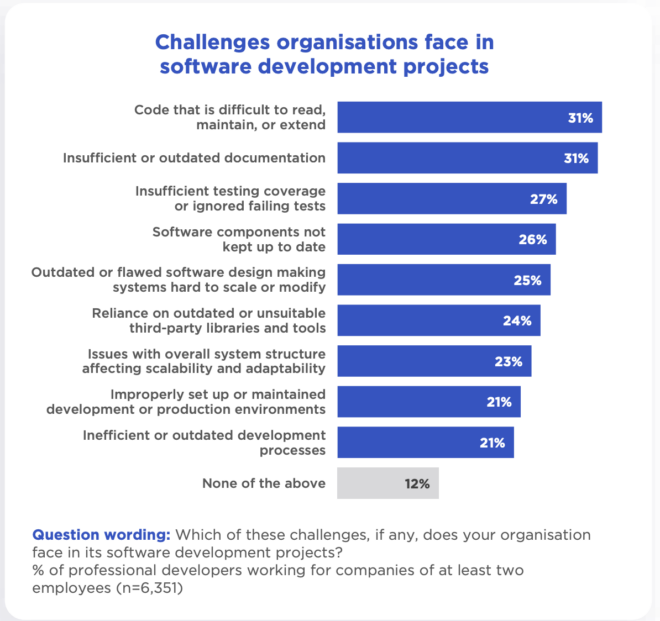
What you should know before you go
TLDR; Over 1400 people attended WWDC25 in Cupertino, California. Each event you attend has TWO locations you need to know: Registration with Security Check and the actual venue. The Sunday registration and event (where you pick up your credentials for the rest of the events along with a swag bag, and a meet-up reception with appetizers and drinks, both alcoholic and non) was at 1 Infinite Place. Monday’s Registration with Security Check is at the Apple Park Visitor Center (10600 N Tantau Ave) and the events (Keynote and State of the Platforms) are at Apple Park (aka corporate headquarters, One Apple Park Way, Apple Campus). Lunch is provided Monday. Tuesday’s Registration and Security Check and the event that you pre-registered and were accepted to are held at the Apple Developer Center (10500 N Tantau Ave, near the Apple Park Visitor Center). Appetizers are provided after the event and no food or drinks are allowed in the rooms for the presentations.
{{ advertisement }}
As a registered Apple Developer ($99 USD/year fee for an individual develop or $199 USD/year for the enterprise program), you should receive and email in mid- to late March that announces the WWDC in June. In that email will be a link to ask to be invited to attend WWDC in person. The email is sent by Apple Developer. If you are invited (depends on how many people ask to be asked what your chances will be), you need to accept the invitation by clicking on the link in the confirmation email and filling out the form with your contact information and the name you want on your badge. Once you do that, then things get interesting and a little intimidating for a first-time participant.
Lots of questions came to mind, especially as being an Apple developer is not my main source of income. The ones I remember the most were:
- Can I get time off from work?
- How long should I stay in California?
- How am I going to get to Cupertino?
- Where will I stay?
- What will I do for meals?
- What should I pack?
Can I get time off from work?
This one was pretty easy. I had already arranged to have afternoons off for the week to watch the presentations that I expected would be 9am to late afternoon Cupertino, California time (meaning noon to early evening East Coast time, where I live and work full time). I knew I had enough time to be able to take the whole week off, I just needed to let my boss know I had been accepted to attend in person and he’s an awesome boss and had no problem with me going to the conference in person.
How long should I stay in California?
The online conference is all week (Monday – Friday). The in-person scheduled events are Sunday – Tuesday. I was planning on attending the in-person events and then watching the rest of the conference online, from the hotel room as my flight home would consume a full day, especially with the time change. In retrospect, I should probably have flown home Wednesday morning and caught up on the session on demand Thursday and Friday and over the weekend as I recovered from jet lag, too. I did not mind staying at the hotel the whole week, I just was not as dedicated to the events once I found out the hotel’s Apple TV system would not link to my iPhone nor to my iPad to play the sessions on the bigger screen. And the free hotel Wi-Fi was not fast enough to stream the sessions reliably. I had to rely on the phone’s cellular connection.
How am I going to get to Cupertino?
The first (and only) time I had gone to Apple headquarters before (January 14, 2008), we had stayed in San Francisco, and we had taken public transportation to get to Cupertino. I knew I did not want to have to do that every day of the conference, so I found out that San Jose airport in California was less than 10 miles from Cupertino. Unfortunately, there are no direct flights from the Boston area (which I expanded to include the New York airports, Manchester [New Hampshire], and Providence [Rhode Island], and even Worcester [Massachusetts]) airports to San Jose, California. The best I could do was Delta Airlines and connecting flights.
- My first choice was BOS->LAX->SJC to get there and SJC->ATL->BOS to get back.
When I booked that, Delta almost immediately sent an email that the hour and half layover in ATL had been changed to 45 minutes and I could change the flight if that didn’t work for me. I researched ATL airport layout and decided to sleep on the decision. That night, I dreamt that I missed the connection, but my bags didn’t and they kept going round and round the luggage carousel in BOS until someone decided to take them. Then, when I showed up at the airport later, my bags were unavailable. I woke up from that nightmare, calmed myself down and fell back asleep…then my dream was that *I* made the connection (I ran fast between gates, at speeds only ever attained in a dream), but my luggage didn’t! I woke up in a sweat, wondering how to get my luggage and would I need to get a ride back to the airport to collect them when they finally arrived? Once I realized it was only a dream, I decided that when I got up, I was changing my return flight! I needed to have enough time for the layover!
- I decided to keep it simple and just fly the return route as the reverse of how I got there, so SJC->LAX->BOS, on the way back.
That gave me a 3-hour layover timeframe. I figured I could find *something* to do in the airport for 3 hours (minus deplaning and boarding time, probably more like a little over 2 hours).
So, my flights were set. I just needed to arrange the trip to and from the Boston airport. We have a local transportation company that I use all the time, so I called them and made the arrangements for pick up to and from. That was probably the easiest part of the process! I was planning on getting a Lyft or Uber for the trip from and to San Jose airport.
Where will I stay?
There are several hotels available in the area and I was worried that they would fill up (not having any idea how many other developers were going to be attending in person). This is when I started asking for advice from anyone else who was attending or had attended in the past to see if I could gain insight into the good, bad, fine, and perfect hotels in the area. Reviews were not helping as I read them on the usual travel sites. They all seemed to range from “Best customer service EVER” to “WORST service, will NEVER stay here again”…for the same hotel. I mean every single hotel has both extremes of review, in about equal percentages. Logic was not going to help me here.
I settled for the Hilton Garden Inn, Cupertino. This is a fine hotel. They advertise as the closest hotel to Apple. Maybe by driving or as-the-crow-flies. I had a room on the 5th floor that had a view of part of Apple Park. That was a plus. It was a 35–45-minute walk to get to the area where the registration for the keynote and platform state of the platform presentations were, though. It was a 10-minute walk to Apple Park itself…to a security gate to get there. Fortunately, the security guard let me in. Unfortunately, he should not have. Knowing the address of where I needed to be would have helped a lot for a first-time attendee. Then, I would have been in the Registration and Security Check line that I was asked to join when they found me wandering around Apple Park hours before they opened the gate to attendees. I will say, though, everyone was kind and understanding. No one I meet made me feel like it was my fault or that they thought I was trying to get one over on them. They realized the mistake and pointed me to the direction I needed to be.
What will I do for meals?
I had no idea if Apple was going to feed us or if I was on my own. I figured I would at least need food I knew I would be able to eat for Wednesday – Friday at any rate. And probably dinners. I looked up restaurants and their menus in the area and decided my best shot would probably be to bring shelf-stable food I could heat and eat in my room. I was planning on bringing a checked bag full of food for the week and then I could use it for bringing back any souvenirs or swag from the conference.
What should I pack?
This was also an easy question to answer. I have an Excel spreadsheet I use for packing on every trip. I enter the number of nights, number of people, and number of laundry trips I expect to need. This last number was added for the two-week vacation I just had in February where the first week was spent in Orlando at Universal Studios and the second week was a cruise. By dedicating a day to laundry, we only had to pack one week of clothes each and had a day to relax before changing from land to sea.
Weather in Cupertino was projected to be warm but not hot, and fair weather (no rain expected). There were no formal activities that I could see planned, and programmers/developers are known for wearing comfortable clothing (jeans and t-shirts), so I figured slacks and shirts would be acceptable. I did pack a long skirt that would pair well with my shirts, too for the first night, as it was registration and a meet and greet. Luckily, there really was no formal or semi-formal events and I did not feel undressed at all.
Day-by-Day Agenda
Saturday
Fly in, check into the hotel, get situated. Unpack the food and take a walk about the hotel. Take lots of pictures!
Sunday
What: Registration and Meet and Greet.
Where: map location to use: 1 Infinite Place. This was the location of Apple Headquarters when last I visited and is NOT within a short walking distance of the Hilton Garden Inn or Apple Park itself. I took an Uber there. It cost $7.18 (plus tip) to get there. Apple had set up a Ride Share area for drop-off and pick up, making in convenient. There was parking available if you drove. I cannot attest to the availably of the parking, though.
The Registration line opened at 4pm. You want to get there before then, like an hour (or two) before the time it starts *to get to know the other people in line with you) or an hour or two after registration opened to sail right in with no line (but then, you miss most of the meet and greet activity and the camaraderie of talking to other people in line waiting).
There were Apple employees available to take your picture (your phone) at the 1 Infinite Place sign as you were walking to enter the queue line. That was very popular!
As we were waiting in the queue line, Apple employees were walking up and down the line, offering bottles of water. No plastic water bottles here! These were aluminum bottles. Once registration opened, the line moved at a steady pace. At registration, you received a swag bag branded with the WWDC25 logo which contained a reusable water bottle, pins, and a short lanyard. You also received a retractable lanyard and a name badge that you need to have accessible as it would be scanned at each event you attend. This name badge has the name you used when you accepted the invitation. The color of the lanyard designated your “standing” at the conference (student, student winner, attendee, employee, and so on).
The meet and greet provided hors ‘de oeuvres at multiple stations in the open-air courtyard. Plenty of seating and tables were provided. As we approached the food, there were a lot of other activities. There were more Apple-employee assisted photo opportunities: the WWDC25 sign and the Developer Heat Map (where you put a pin in the world map to represent where you are from). Other activities included a conversation starter table where you get a piece of cardboard and a sharpie to write what you want to talk about. Then you attach it to your lanyard with magnets. This cardboard is impregnated with seeds that you can plant after the conference (instructions are printed on the card). Mine are growing in a pot inside the house so I can watch the germination.
I spotted Paul Hogan (Hacking with Swift) in the meet and greet area so and I went up to him and he recognized me when I introduced myself. He teaches a free online course in Swift and SwiftUI programming. He invited me to his off-campus get together on Tuesday night. It was a 10-minute walk from my hotel to where he was talking so I told him I’d be thrilled to be there.
There was enough food for my dinner, but then I don’t eat a big dinner, so I don’t need much to be full. The food appeared to be abundant, so if you eat more than I do, you could probably have a good meal. They had alcoholic (you must show proper ID) and non-alcoholic drinks in abundance, and I saw they kept refilling the food and drinks. I did not stay until the end of the party. I scheduled a Uber for the ride back to the hotel. It was $10.41(plus tip) to get back to the hotel after the event.
Monday
What: Keynote (morning), lunch, and State of the Platform (afternoon).
Where: map address to use: Apple Park Visitor Center (10600 N Tantau Ave)
This is the day where knowing the street address of where I needed to be would have prevented my arrival at a security gate near Apple Park and the string of events that eventually lead to my joining the queue for registration and Security Check hours after I would have normally been there. Now, that said, I did have a great time by showing up at the security gate early and being let in. I was given a ride in an electric golf cart (two of them, as the first one either wasn’t charged up or was having engine/battery problems and we didn’t get very far down the path) to Apple Park. Then, I walked around, wondering how many people there were going to be. I talked to some Apple employees setting up and I took some pictures of the area and how devoid of attendees it was. I heard employees planning and discussing what they needed to do once people started to show up. I talked to someone in Guest Services about what Guest Services is (they provide assistance to attendees that need extra help). We talked about why there were different color chairs and a special section for the student attendees and student winners. I asked if the back section was for the attendees if the front section was for the students. I was told that only the roped off section in the front was for the student attendees and that I would be able to sit anywhere.
Then, as I was walking around, admiring the cafeteria areas, and taking photos of the employees measuring the distance between the picnic tables and each chair, someone came up to me and asked if I had registered. I said yesterday, yes I had. They said, no today. There was a registration area and Security Check I needed to go through. I said no. They asked how I got in and I said, well, I used Google Maps to walk to Apple Park, ended up at a security gate, and was let in. Oh! Well, could I please wait here while she checks something out? Sure. I sat down next to someone else, who also appeared to be an attendee (not an employee). So, we started talking. I wasn’t sure how he got in, but he also hadn’t gone though the Security Check, so I ratted him out when she came back. The three of us walked to Registration and Security Check. He said he had some friends near the head of the line and excused himself as I joined the end of the line that was still forming. While in line, I heard some guys talking about their friend who had been in Apple Park itself, and was ratted out by another attendee (opps…) and that he was escorted out. They were talking as if he had gone to attendee jail, and I wasn’t going to say anything to correct them. He came over to them (they were different friends than the ones he was originally looking for). And I waved to him, and said “Hello, again,” and then I told him his friends thought I had gotten him thrown in jail. He explained to them that I was the one he was talking about, and no; no jail for us. Once they opened the door for Registration, the line moved steadily, with multiple people scanning attendees in and then on to the Security Check. Once through security, it was a short walk back to Apple Park. I found a good seat in the front section and sat my hoodie and WWDC25 bag down on the chair. I then went and got a large hot tea and went back to my seat to get ready for the Keynote presentation. And sure enough….my fellow gate crasher sat down next to me! We chatted, I apologized for ratting him out and told him I was glad he didn’t really end up in attendee jail.
Tim Cook appeared live on the stage (and everyone stood up to take pictures of him, preventing people in the back from being able to see him). He did a live intro to the Keynote pre-recorded event. If you remember, it started with a race car driving around the top of Apple Park. Darn if a bunch of us didn’t turn around to look at the building to see if there was a race car up there (there wasn’t). As the keynote continued, it was interesting to see what got big applause from the audience. Everything was met with enthusiasm and anticipation that only devote fanboys can provide. The biggest applause that I heard was for the announcement about On Hold and letting you put the phone down and living your life, doing other things instead of listening to “Please hold, your call is very important to us….please hold, the next available representative will be with you shortly….your call is very important….” On and on and on. Now, Apple will intercept when the representative connects and tell THEM, “Please hold, the call will be connected now…” and then notify *you* so you can resume the call. The crowd went WILD!
After the keynote, Apple provided lunch. There were many stations with different options to pick from (vegetarian, spicy, seafood, Mediterranean, Italian and so on and that was only one side of the cafeteria. I’m not sure if it was repeated on the other side or if there were different items over there. Everyone got food and drinks and then headed for the picnic tables. And sure enough, there is my new best friend, and an empty seat. We had lunch together. After lunch, I moved up about 5 rows and didn’t see him again.
The State of the Platforms presentation was after lunch. We all grabbed a cold drink and sat down for the presentation. No as much applause this time. It was interesting and informative. Unfortunately, I do not remember much about it, though. After the State of the Platforms, they mentioned break-out groups that I did not understand what they were for or what people would be doing. I did not see anything I thought I absolutely had to do, so I walked from Apple Park to the Visitor’s Center and then to the hotel. I took my time walking, took a lot of photos of plants I wanted to explore when I got home, and when I got back to the hotel, I made dinner, collapsed, took a shower, and went to bed.
Tuesday
What: Pre-arranged break-out sessions.
Where: maps location to use: Apple Developer Center, 10500 N Tantau Ave, near the Apple Park Visitor Center from Monday
This day is for the groups and discussions that you pre-registered and were accepted for. This is also another photo opportunity after you get scanned in.
Food and drink are provided’ no food and drink are allowed into the theaters, though. Interesting presentation.
Afterwards, I walked over to the Apple Park Visitor Center and went shopping. I bought two T-shirts (Apple Park Rainbow and Apple in colors) and two Apple pens (rose gold and gold) because I was told they were worth it.
I then walked back to the hotel, leisurely, and just a little quicker than Monday’s trip.
Tuesday night, I walked down to the Hyatt House for the Hacking with Swift Live get-together. That was very interesting and the swag bag from that was worth the trip itself. Paul was talking about his course, and how he was planning on revamping it and what did we want to see in the class and he was talking notes it was a great time.
Would I do it again?
It’s been about a month and after thinking about it….my answer remains the same as it was when I first got home. Yes! In a heartbeat! If I get asked to ask to be invited, I will ask and I will hope to be accepted again. I might try a different hotel to see what else is available and offered, but the Hilton Garden Inn Cupertino is a fine hotel. The weather was great, not too hot and not humid at all. There is nothing like spending a few days with other Apple enthusiastic developers and using their infectious attitudes to power you through the day.