User Experience (UX) Design principles play a key role in increasing customer experience. UX principles focus on creating products that are user-friendly and meaningful to use.
According to the research paper published by Core, If you want to design a user-friendly interface, white-label service providers who are experts in designing can help you out. White-label web development companies have UI/UX experts who know how to place each UI element in your product. So, white-label agencies can help you build a more responsive and highly interactive design to help the users move around the website.
Here are the things white-label agencies take care of while designing the UI/UX of your product.
6 UX Design Principles for Increasing Customer Experience
#1 Simple and Clear Designs
Keeping your website design simple and clear is an integral part of your UX strategy. This would involve defining the navigation menus clearly. You must design intuitive design layouts and use effective language.
Make sure to add inputs and messages along the design wherever needed. It will help enhance the experience of the user. Your white-label design service provider will prioritize simplicity while crafting the solution. They will use the existing successful websites as their guide to define a clean and organized layout.
The services will devise a strategy to make navigation intuitive and guided. This would help people move around without being stuck at any point. Moreover, they can plan for a “one-task, one-screen” layout that avoids clutter.
According to the research paper published by Core, simplicity in design is about going deep into your user’s minds. There are 3 ways to achieve simplicity in design:
• Maintain clarity: Understand and design for your users’ main goals
• Make use of automation: Design for a minimum amount of conscious and cognitive effort
• Limit options: Design for a strong “information scent”
#2 Crafting Responsive Designs
Your users access the same websites across devices and resolutions. For instance, a user may access the website on the Chrome browser on their Android tablet. Another user may access the website on their iPhone browser.
It is also possible the same user opens the website on an Android phone and tablet simultaneously. Responsive designs will automatically adapt to the platform’s needs and screen sizes. The design will stay consistent, and users will not face any friction while moving around. This adaptability will enhance the user’s experience.
Your white-label service provider can help you implement the responsive design layout. They are crucial in imagining and testing responsive designs. They will thoroughly test the design and address layout issues in advance.
#3 Ensuring Design Consistency
Consistency is key to keeping your users happy. You must ensure your design is aligned with your brand’s identity. Each element must be cohesive and defined.
You must add the brand’s color scheme, typography, and design styles while creating the website. This would make it recognizable and relatable to the users. You can improve the overall appearance and ensure a professional design outcome.
A white-label website design and development service provider works with defined guidelines. They are aware of the design expectations and nuances. As a result, companies can offer clean and consistent designs. Companies would design the wireframe to prototype to eliminate inconsistencies and provide a smooth layout.
#4 Well-defined Information Architecture
Information flow is pivotal in enhancing the user’s experience. You must define a logical movement and the organization of the content. When the user moves from one particular information to another, they must sense an intuitive flow.
This would increase the user’s engagement on the website and allow them to find the information faster. You can connect with your white-label service provider to define the sitemap and wireframes for your website. This would establish an organized information flow. You can design the user journeys and map them in your website design.
Companies can also help you conduct usability tests and validate the information flow for engagement.
#5 Iterative Design with Feedback Loops
Knowing what your users think of the design is crucial for designing an appropriate website. You must ensure you have a feedback loop that brings back the messages from the user. This would help build a user-centric website.
You must use an iterative design strategy to implement the loops and leverage them to avail the feedback.
You must have defined mechanisms to help collect the user’s feedback. This would include surveys and analytics tools. White-label service providers can implement these feedback loops and incorporate iterative design for excellent user insights.
Companies can use user insights to build an optimized website aligned with the user’s preferences and needs.
#6 Accessibility Design Considerations
Diverse users, including people with disabilities, will access your website. You must prepare your website for all user types. Ensure the website is aligned with the ethical design considerations while designing for web accessibility.
Implementation: The white-label service provider is well aware of accessibility guidelines. Their understanding of accessibility standards would help them implement the right headings and alt+text for images.
Moreover, they would ensure the design is accessible via screen readers and other inputs. This would address all the barriers and ensure inclusivity.
Conclusion
It is crucial to create UX-led white-label websites. This would enhance your design strategy and extend exceptional results. You can elevate your user’s experience by implementing consistent and clear designs.
Moreover, it offers an organized information architecture and accessible design that boosts the website’s quality. When your website meets the functional, aesthetic, and quality standards, it is usable, user-friendly, and highly engaging.
This would improve the session length and the conversion rate for your business. Prioritizing UX design principles in your website design is no longer a strategy; it is the definition of a successful website.
“Why bother with it? I let it run in the background and focus on more important DevOps work.” — a random DevOps Engineer at Reddit r/devops
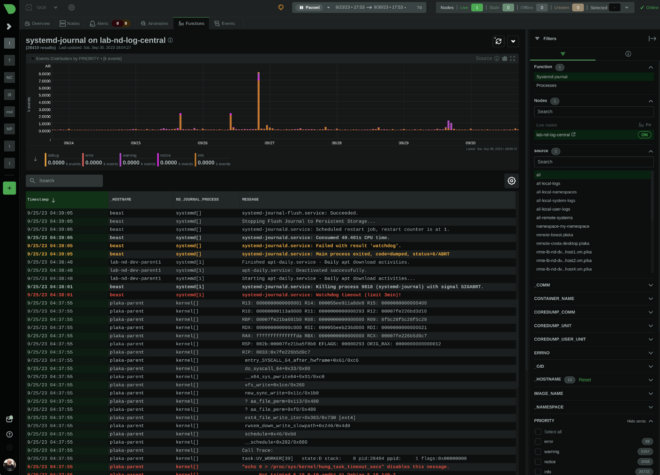
In an era where technology is evolving at breakneck speeds, it’s easy to overlook the tools that are right under our noses. One such underutilized powerhouse is the systemd journal. For many, it’s a mere tool to check the status of systemd service units or to tail the most recent events (journalctl -f). Others who do mainly container work, ignore even its existence.
What is the purpose of systemd-journal?
However, the systemd journal includes very important information. Kernel errors, application crashes, out of memory process kills, storage related anomalies, crucial security intel like ssh or sudo attempts and security audit logs, connection / disconnection errors, network related problems, and a lot more. The system journal is brimming with data that can offer deep insights into the health and security of our systems and still many professional system and devops engineers tend to ignore it.
Of course we use logs management systems, like Loki, Elastic, Splunk, DataDog, etc. But do we really go through the burden to configure our logs pipeline (and accept the additional cost) to push systemd journal logs to them? We usually don’t.
On top of this, what if I told you that there’s an untapped reservoir of potential within the systemd journal? A potential that could revolutionize the way developers, sysadmins, and DevOps professionals approach logging, troubleshooting, and monitoring.
systemd journal isn’t just a logging tool; it’s an intricate system that offers dynamic fields for every log entry. Yes, you read right. Each log line may have its own unique fields, annotating and tagging it with any number of additional name-value pairs (and the value part can be even binary data). This is unlike what most log management systems do. Most of them are optimized for logs that are uniform, like a table, with common fields among all the entries. systemd journal on the other hand, is optimized for managing an arbitrary number of fields on each log entry, without any uniformity. This feature gives this tool amazing power.
Check for example coredumps. systemd developers have annotated all applications crashes with a plethora of information, including environment variables, mount info, process status information, open files, signals, and everything that was available at the time the application crashed.
Now, imagine a world where application developers don’t just log errors, but annotate those logs with rich information: the request path, internal component states, source and destination details, and everything related to identify the exact case and state this log line appeared. How much time such error logging would save? It would be a game-changer, enabling faster troubleshooting, precise error tracking, and efficient service maintenance.
All this power is hidden behind a very cryptic journalctl command. So, at Netdata we decided to reveal this power and make it accessible to everyone.
Try it for yourself in one of our Netdata demo rooms here.
This blog is contributed to Developer Nation by Netdata
As part of a modern software development team, you’re asked to do a lot. You’re supposed to build faster, release more frequently, crush bugs, and integrate testing suites along the way. You’re supposed to implement and practice a strong DevOps culture, read entire novels about SRE best practices, go agile, or add a bunch of Scrum ceremonies to everyone’s calendar. Every week, the industry recommends that you “shift-left” another part of the DevOps pipeline, to the point where you’re supposed to handle everything from unit testing to production deployment optimization from day one.
While you might have some experience in monitoring software, the reality is that as an aggregate, some others around you probably don’t. According to the Stack Overflow Developer Survey 2020, nearly 40% of developers have less than 5 years of professional experience. There’s not enough time for anyone to learn all these DevOps tools and best practices while also putting meaningful code into a GitHub repository on a regular basis.
Monitoring, and the metrics data it creates, can be a powerful way to encourage DevOps best practices through a common language, and implementing it doesn’t have to be complicated or time-consuming. By combining a DevOps mindset with a “full-stack” monitoring tool, you can start getting instant feedback about the performance and availability of what you’re trying to build—without waiting another 5 years for your team’s DevOps experience to catch up.
If your team has already settled on a monitoring tool, you can start applying these best practices today. If you’re still looking for the right piece of kit, you can start making informed tooling decisions based on what’s going to strengthen your team.
Focus on infrastructure monitoring first
When we talk about monitoring software for DevOps teams, we’re talking primarily about infrastructure monitoring. Infrastructure monitoring is the practice of collecting metrics data about the performance and availability of an application’s “full stack.” That’s everything including the hardware, any virtualized environment, the operating system, and any services (like databases, message queues, or web servers) that might make your application possible.
Depending on the full stack’s complexity, infrastructure monitoring can mean keeping an eye on a single virtual machine (VM) running on Google Cloud Platform (GCP), a Kubernetes (k8s) deployment with dozens of ephemeral nodes that scale horizontally during periods of high usage, or anything in between.
Here’s some key infrastructure metrics to keep an eye on using your monitoring tool (Netdata included):
If you can collect eBPF metrics, that’s even better, even if you aren’t experienced enough to make sense of them yet. eBPF metrics are still very much the cutting edge of infrastructure monitoring, providing extremely granular detail into exactly how the Linux kernel deals with your full stack, so there’s still a lot of flux in recommendations and best practices.
Monitor performance and availability in every environment
Modern DevOps teams should be monitoring the full stack no matter where it runs. This presents quite a large break from tradition, where the operations (Ops) team handled monitoring only once the application was running in production. The perception was that seeing users interact with a full stack was the only way to catch real bugs.
The latest best practices acknowledge that it’s possible—even inevitable—to catch bugs early by monitoring everywhere. That starts with local development servers and extends to any number of testing, staging, or production environments. That also means the monitoring tool should work whether the application is running off the latest M1 Macbook Air or in a multi-cloud deployment across dozens of virtual machines (VMs).
Before you go rushing into your next release process, take time to develop the tooling to monitor in more places. That might mean creating a custom Dockerfile for local development, or adding hooks into your CI/CD toolchain to deploy a fresh staging environment every time a developer reaches a milestone.
How’s this for an easy deployment experience in any environment?
Collect everything, worry about it when you need it
The only way to know that something is going wrong with your application’s infrastructure is to have the data to support it. One common practice is to vacuum up every metric, store it for 2-3 weeks, and have it available if you need to go back in time and root cause an issue or outage.
One way to ensure you’re collecting everything is to choose a tool with high granularity. Every infrastructure monitoring tool collects and visualizes metrics at a specific granularity, which is another way of talking about the time period between one point of collection and the next.
One data point every 60 seconds = low granularity One data point every 1 second = high granularity If you have a transitive-but-critical error that comes and goes within 5 seconds, a low-granularity solution might not even show a blip, which means you still don’t know anything went wrong in the first place.
With low granularity, metrics are averaged out over long periods of time, which has the unwanted effect of flattening what should be a worrying spikes into nothing more than a blip in the noise.
Netdata itself uses an internal time-series database for storing per-second metrics in an efficient way, which gives you tons of flexibility to find the sweet spot between disk space considerations and keeping historical metrics around long enough for proper analysis.
Some DevOps teams even use tools like (e)BPF, which collect and visualize metrics with an event granularity, which means they can show you every event, and not just an average/minimum/maximum of data between two points in time.
Break down silos with metrics
One of the DevOps mindset’s core purposes is to break down existing silos between what used to be separate development (Dev) and operations (Ops) teams. In the past, the Dev team finished writing code, flung across the fence to the Ops team, and wiped their hands clean from whatever came next. The Ops team then spent their days putting out fires and understanding how the application worked.
DevOps is designed to stop this unproductive cycle, but it only works if everyone has access to the same platform and uses the same language: metrics. Choose a tool that’s accessible to everyone who touches application code or controls the production environment. That doesn’t mean having one person who controls the infrastructure monitoring dashboards and lets the rest of the organization look at it in read-only mode.
Make sure your monitoring tool encourages the sharing of information. Let anyone on your team, no matter their role, peek at your configurations or dashboards. By looking over your shoulder, they might learn something valuable, like a metric they’d previously overlooked or a unique troubleshooting strategy. On the other hand, the tool should also let anyone experiment and explore in a “sandbox” that doesn’t affect the core health and availability dashboards.
For example, Netdata Cloud uses the concepts of War Rooms, which are shared containers for DevOps teams who need to do infrastructure monitoring. Every node, alert, and custom dashboard in that War Room is shared between everyone, but each team member can freely create, reconfigure, and learn. No more keys to the dashboarding kingdom, and no more worrying about messing up someone else’s perfectly-crafted troubleshooting experience.
Bubble it up into continuous monitoring
While continuous integration (CI) and continuous delivery (CD; CI/CD) have gotten all the attention, a lot of DevOps practitioners have forgotten about continuous monitoring (CM). This practice helps DevOps teams track, identify, and make decisions from all collected metrics, across all environments, in real time.
While some consider CM the last part of the DevOps pipeline—the practice of monitoring an application in production—other organizations bring CM to the entire CI/CD toolchain, monitoring internal processes and tooling to identify issues before being released into the wild.
With a sophisticated CM strategy in place, your team can better respond to ongoing incidents, with the added benefit of making leaps in the 4 key metrics for DevOps success: mean time to acknowledge (MTTA), mean time to recovery (MTTR), mean time between failures (MTBF), and mean time to failure (MTTF). You’ll improve company-wide visibility into the performance and availability of its stack, and you’ll end up driving real business results, like happier users and improved retention. Because Netdata deploys (easily) everywhere, has highly-granular metrics, and lets users of all experience levels explore and learn their infrastructure, it’s perfect for leveling up a DevOp team with CM.
Don’t have a DevOps monitoring tool yet?
The IT infrastructure monitoring tools that make all these best practices come to life come in a huge variety of shapes and sizes, from open-source toolchains you cobble together on your own to enterprise-friendly monoliths that do everything but cost a ton.
Because there are so many moving parts, a lot of developers and DevOps teams hesitate when choosing an IT monitoring tool, and then end up with something that doesn’t actually empower them, knock down silos between teams, or ramp up the speed of development.
One choice that enables all of the above best practices, and many more, is Netdata. Download the free and open-source Netdata Agent to start implementing DevOps best practices and improve team’s performance know-how with a free, open-source monitoring tool.
Once you’re seeing metrics with per-second granularity, familiarize yourself with Netdata’s documentation and guides to explore more opportunities to explore, troubleshoot, and resolve even the most complex of full-stack issues.
This blog is contributed to Developer Nation by Netdata
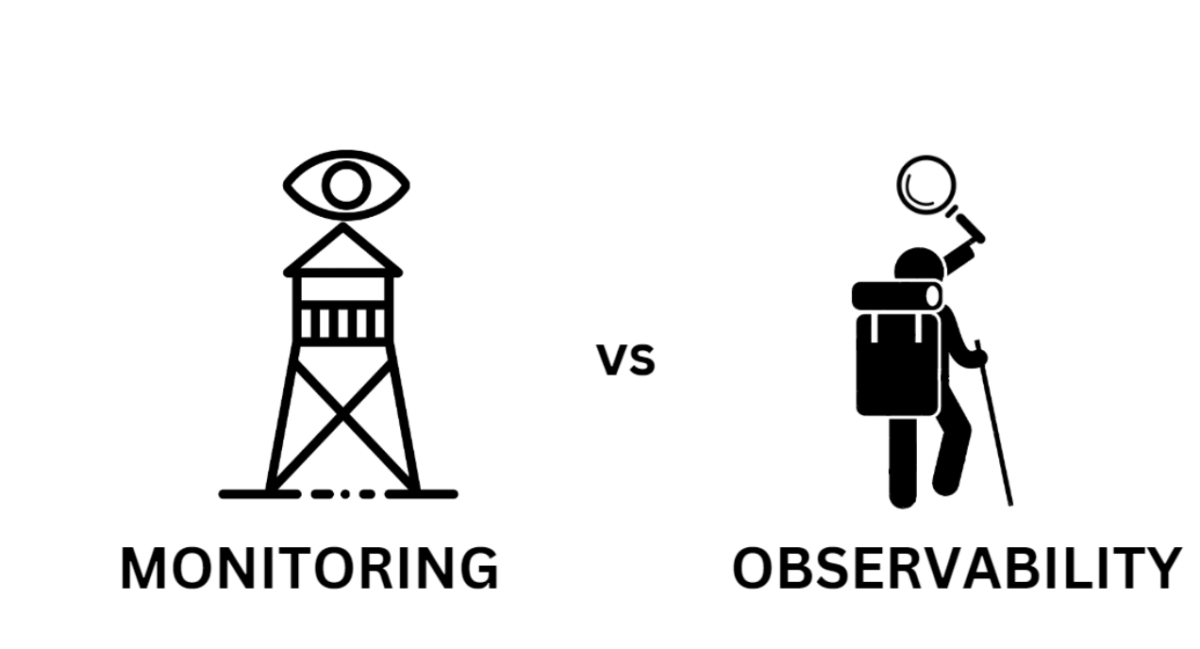
As systems increasingly shift towards distributed architectures to deliver application services, the roles of monitoring and observability have never been more crucial. Monitoring delivers the situational awareness you need to detect issues, while observability goes a step further, offering the analytical depth to understand the root cause of those issues.
Understanding the nuanced differences between monitoring and observability is crucial for anyone responsible for system health and performance. In dissecting these methodologies, we’ll explore their unique strengths, dive into practical applications, and illuminate how to strategically employ each to enhance operational outcomes.
To set the stage, consider a real-world scenario that many of us have encountered: It’s 3 a.m., and you get an alert that a critical service is down. Traditional monitoring tools may tell you what’s wrong, but they won’t necessarily tell you why it’s happening leaving that part up to you. With observability, the tool enables you to explore your system’s internal state and uncover the root cause in a faster and easier manner.
The Conceptual Framework
Monitoring has its roots in the early days of computing, dating back to mainframes and the first networked systems. The primary objective was straightforward: keep the system up and running. Threshold-based alerts and basic metrics like CPU usage, memory consumption, and disk I/O were the mainstay. These metrics provided a snapshot but often lacked the context needed for debugging complex issues.
Observability, on the other hand, is a relatively new paradigm, inspired by control theory and complex systems theory. It came to prominence with the rise of microservices, container orchestration, and cloud-native technologies. Unlike monitoring, which focuses on known problems, observability is designed to help you understand unknown issues. The concept gained traction as systems became too complex to understand merely through predefined metrics or logs.
Monitoring: The Watchtower
Monitoring is about gathering data to answer known questions. These questions usually take the form of metrics, alerts, and logs configured ahead of time. In essence, monitoring systems act as a watchtower, constantly scanning for pre-defined conditions and alerting you when something goes awry. The approach is inherently reactive; you set up alerts based on what you think will go wrong and wait.
For instance, you might set an alert for when CPU usage exceeds 90% for a prolonged period. While this gives you valuable information, it doesn’t offer insights into why this event is occurring. Was there a sudden spike in user traffic, or is there an inefficient code loop causing the CPU to max out?
Observability: The Explorer
Observability is a more dynamic concept, focusing on the ability to ask arbitrary questions about your system, especially questions you didn’t know you needed to ask. Think of observability as an explorer equipped with a map, compass, and tools that allow you to discover and navigate unknown territories of your system. With observability, you can dig deeper into high-cardinality data, enabling you to explore the “why” behind the issues.
For example, you may notice that latency has increased for a particular service. Observability tools will allow you to drill down into granular data, like traces or event logs, to identify the root cause, whether it be an inefficient database query, network issues, or something else entirely.
Key Differences between Monitoring & Observability
Data
Monitoring and observability rely heavily on these three fundamental data types: metrics, logs and traces. However the approach taken in collecting, examining and utilizing this data can differ significantly.
Both monitoring and observability rely on data, but the kinds of data they use and how they use it can differ substantially.
Metrics in Monitoring vs Observability
Metrics serve as the backbone of both monitoring and observability, providing numerical data that is collected over time. However, the granularity, flexibility, and usage of these metrics differ substantially between the two paradigms.
Monitoring: Predefined and Aggregate Metrics
In a monitoring setup, metrics are often predefined and tend to be aggregate values, such as averages or sums calculated over a specific time window. These metrics are designed to trigger alerts based on known thresholds. For example, you might track the average CPU usage over a five-minute window and set an alert if it exceeds 90%. While this approach is effective for catching known issues, it lacks the context needed to understand why a problem is occurring.
Observability: High-Fidelity, High-Granularity and Context-Rich Metrics
Observability platforms go beyond merely collecting metrics; they focus on high-granularity, real-time metrics that can be dissected and queried in various ways. Here, you’re not limited to predefined aggregate values. You can explore metrics like request latency at the 99th percentile over a one-second interval or look at the distribution of database query times for a particular set of conditions. This depth allows for a more nuanced understanding of system behavior, enabling you to pinpoint issues down to their root cause.
A critical aspect that is often overlooked is the need for real-time, high-fidelity metrics, which are metrics sampled at very high frequencies, often per second. In a system where millions of transactions are happening every minute, a five-minute average could hide critical spikes that may indicate system failure or degradation. Observability platforms are generally better suited to provide this level of granularity than traditional monitoring tools.
Logs: Event-Driven in Monitoring vs Queryable in Observability
Logs provide a detailed account of events and are fundamental to both monitoring and observability. However, the treatment differs.
Monitoring: Event-Driven Logs
In monitoring systems, logs are often used for event-driven alerting. For instance, a log entry indicating an elevated permissions login action might trigger an alert for potential security concerns. These logs are essential but are typically consulted only when an issue has already been flagged by the monitoring system.
Observability: Queryable Logs
In observability platforms, logs are not just passive records; they are queryable data points that can be integrated with metrics and traces for a fuller picture of system behavior. You can dynamically query logs to investigate anomalies in real-time, correlating them with other high-cardinality data to understand the ‘why’ behind an issue.
Proactive vs Reactive
The second key difference lies in how these approaches are generally used to interact with the system.
Monitoring: Set Alerts and React
Monitoring is generally reactive. You set up alerts for known issues, and when those alerts go off, you react. It’s like having a fire alarm; it will notify you when there’s a fire, but it won’t tell you how the fire started, or how to prevent it in the future.
Observability: Continuous Exploration
Observability, by contrast, is more proactive. With an observability platform, you’re not just waiting for things to break. You’re continually exploring your data to understand how your system behaves under different conditions. This allows for more preventive measures and enables engineers to understand the system’s behavior deeply.
Opinionated Dashboards and Charts
Navigating the sprawling landscape of system data can be a daunting task, particularly as systems scale and evolve. Both monitoring and observability tools offer dashboards and charts as a solution to this challenge, but the philosophy and functionality behind them can differ significantly.
Monitoring: Pre-Built and Prescriptive Dashboards
In the realm of monitoring, dashboards are often pre-built and prescriptive, designed to highlight key performance indicators (KPIs) and metrics that are generally considered important for the majority of use-cases. For instance, a pre-configured dashboard for a database might focus on query performance, CPU usage, and memory consumption. These dashboards serve as a quick way to gauge the health of specific components within your system.
Quick Setup: Pre-built dashboards require little to no configuration, making them quick to deploy.
Best Practices: These dashboards are often designed based on industry best practices, providing a tried-and-true set of metrics that most organizations should monitor.
Lack of Flexibility: Pre-built dashboards are not always tailored to your specific needs and might lack the ability to perform ad-hoc queries or deep dives.
Surface-Level Insights: While useful for a quick status check, these dashboards may not provide the contextual data needed to understand the root cause of an issue.
Observability: Customizable and Exploratory Dashboards
Contrastingly, observability platforms often allow for much greater customization and flexibility in dashboard creation. You can build your own dashboards that focus on the metrics most relevant to your specific application or business needs. Moreover, you can create ad-hoc queries to explore your data in real-time.
Deep Insights: Custom dashboards allow you to drill down into high-cardinality data, providing nuanced insights that can lead to effective problem-solving.
Contextual Understanding: Because you can tailor your dashboard to include a wide range of metrics, logs, and traces, you get a more contextual view of system behavior.
Complexity: The flexibility comes at the cost of complexity. Building custom dashboards often requires a deep understanding of the data model and query language of the observability platform.
Time-Consuming: Crafting a dashboard that provides valuable insights can be a time-consuming process, especially if you’re starting from scratch.
Netdata aims to deliver the best of both worlds by giving you out-of-the-box opinionated, powerful, flexible, customizable dashboards for every single metric.
Real-World Applications: Monitoring vs Observability
Understanding the key differences between monitoring and observability is pivotal, but these concepts are best illustrated through real-world use cases. Below, we delve into some sample scenarios where each approach excels, offering insights into their practical applications.
Network Performance
Monitoring tools are incredibly effective for tracking network performance metrics like latency, packet loss, and throughput. These metrics are often predefined, allowing system administrators to quickly identify issues affecting network reliability. For example, if a VPN connection experiences high packet loss, monitoring tools can trigger an alert, prompting immediate action.
Debugging Microservices
In a microservices architecture, services are loosely coupled but have to work in harmony. When latency spikes in one service, it can be a herculean task to pinpoint the issue. This is where observability shines. By leveraging high-cardinality data and dynamic queries, engineers can dissect interactions between services at a granular level, identifying bottlenecks or failures that are not immediately obvious.
Case Study: Transitioning from Monitoring to Observability
Consider a real-world example of a SaaS company that initially relied solely on monitoring tools. As their application grew in complexity and customer base, they started noticing unexplained latency issues affecting their API. Traditional monitoring tools could indicate that latency had increased but couldn’t offer insights into why it was happening.
The company then transitioned to an observability platform, enabling them to drill down into granular metrics and traces. They discovered that the latency was tied to a specific database query that only became problematic under certain conditions. Using observability, they could identify the issue, fix the inefficient query, and substantially improve their API response times. This transition not only solved their immediate problem but equipped them with the tools to proactively identify and address issues in the future.
Synergy and Evolution: The Future of Monitoring and Observability
The choice between monitoring and observability isn’t binary; often, they can complement each other. Monitoring provides the guardrails that keep your system running smoothly, while observability gives you the tools to understand your system deeply, especially as it grows in complexity.
As we continue to push the boundaries of what’s possible in software development and system architecture, both monitoring and observability paradigms are evolving to meet new challenges and leverage emerging technologies. The sheer volume of data generated by modern systems is often too vast for humans to analyze in real-time. AI and machine learning algorithms can sift through this sea of information to detect anomalies and even predict issues before they occur. For example, machine learning models can be trained to recognize the signs of an impending system failure, such as subtle but unusual patterns in request latency or CPU utilization, allowing for preemptive action.
Monitoring and observability serve distinct but complementary roles in the management of modern software systems. Monitoring provides a reactive approach to known issues, offering immediate alerts for predefined conditions. It excels in areas like network performance and infrastructure health, acting as a first line of defense against system failures. Observability, on the other hand, allows for a more proactive and exploratory interaction with your system. It shines in complex, dynamic environments, enabling teams to understand the ‘why’ behind system behavior, particularly in microservices architectures and real-world debugging scenarios.
Netdata: Real-Time Metrics Meet Deep Insights
Netdata offers capabilities that span both monitoring and observability. It delivers real-time, per-second metrics, making it a powerful resource for those in need of high-fidelity data. Netdata provides out-of-the-box dashboards for every single metric as well as the capability to build custom dashboards, bridging the gap between static monitoring views and the dynamic, exploratory nature of observability. Whether you’re looking to simply keep an eye on key performance indicators or need to dig deep into system behavior, Netdata offers a balanced, versatile solution.
This blog is contributed to Developer Nation by Netdata
Properly monitoring the health and performance of Docker containers is an essential skill for solo developers and large teams alike. As your infrastructure grows in complexity, it’s important to streamline every facet of the performance of your apps/services. Plus, it’s essential that the tools you use to make those performance decisions work across teams, and allow for complex scaling architectures.
Netdata does all that, and thanks to our Docker container collector, you can now monitor the health and performance of your Docker containers in real-time.
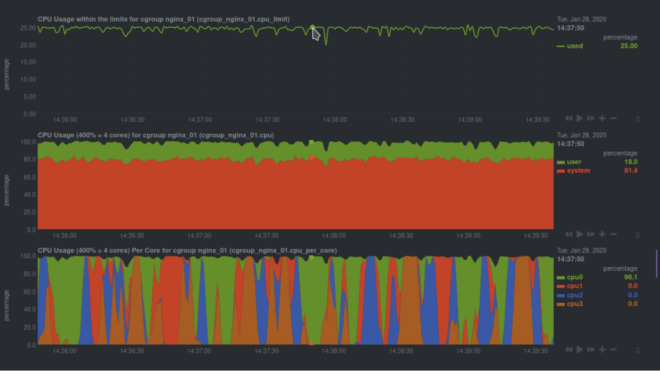
With Docker container monitoring enabled via cgroups, you get real-time, interactive charts showing key CPU, memory, disk I/O, and networking of entire containers. Plus, you can use other collectors to monitor the specific applications or services running inside Docker containers.
With these per-second metrics at your fingertips, you can get instant notifications about outages, performance hiccups, or excessive resource usage, visually identify the anomaly, and fix the root cause faster.
What is Docker?
Docker is a virtualization platform that helps developers deploy their software in reproducible and isolated packages called containers. These containers have everything the software needs to run properly, including libraries, tools, and their application’s source code or binaries. And because these packages contain everything the application needs, it runs everywhere, isolating problems where code works in testing, but not production.
Docker containers are a popular platform for distributing software via Docker Hub, as we do for Netdata itself. But perhaps more importantly, containers are now being “orchestrated” with programs like Docker Compose, and platforms like Kubernetes and Docker Swarm. DevOps teams also use containers to orchestrate their microservices architectures, making them a fundamental component of scalable deployments.
How Netdata monitors Docker containers
Netdata uses control groups—most often referred to as cgroups—to monitor Docker containers. cgroups is a Linux kernel feature that limits and tracks the resource usage of a collection of processes. When you combine resource limits with process isolation (thanks, namespaces!), you get what we commonly refer to as containers.
Linux uses virtual files, usually placed at /sys/fs/cgroup/, to report the existing containers and their resource usage. Netdata scans these files/directories every few seconds (configurable via check for new cgroups every in netdata.conf) to find added or removed cgroups.
The best part about monitoring Docker containers with Netdata is that it’s zero-configuration. If you have Docker containers running when you install Netdata, it’ll auto-detect them and start monitoring their metrics. If you spin up Docker containers after installing Netdata, restart it with sudo service netdata restart or the appropriate variant for your system, and you’ll be up and running!
Read more about Netdata’s cgroup collector in our documentation.
View many containers at-a-glance
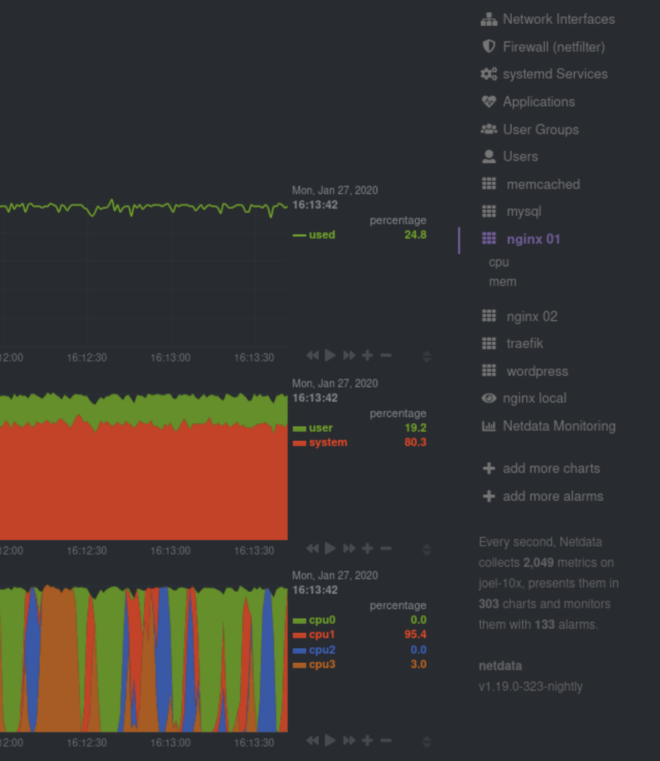
Netdata auto-detects running containers and auto-populates the right-hand menu with their IDs or container names, based on the configuration of your system. This interface is expandable to any number of Docker containers you want to monitor with Netdata, whether it’s 1, 100, or 1,000.
Netdata also uses its meaningful presentation to organize CPU and memory charts into families, so you can quickly understand which containers are using the most CPU, memory, disk I/O, or networking, and begin correlating that with other metrics from your system.
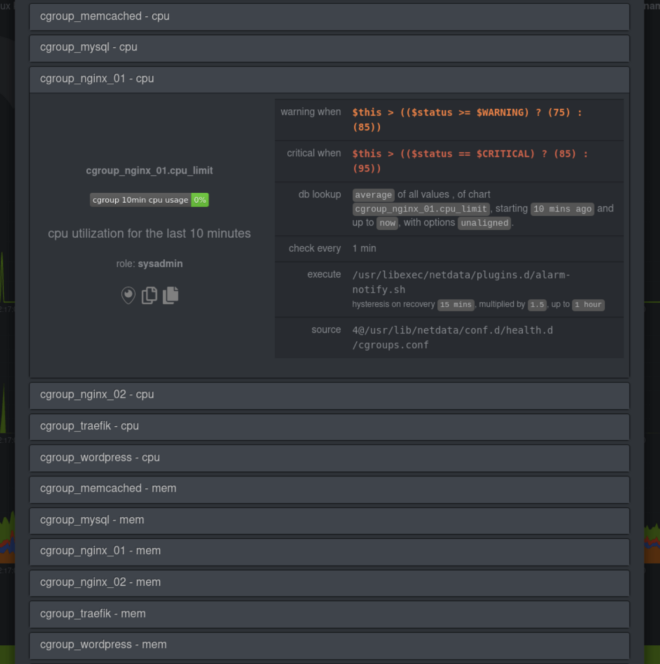
Get alarms when containers go awry
Netdata comes with pre-configured CPU and memory alarms for every running Docker container. Once Netdata auto-detects a Docker container, it initializes three alarms: RAM usage, RAM+swap usage, and CPU utilization for the cgroup. These alarms calculate their usage based on the cgroup limits you set, so they’re completely dynamic to any Docker setup.
You can, of course, edit your health.d/cgroups.conf file to modify the existing alarms or create new ones entirely.
Dive into real-time metrics for containerized apps and services
Netdata’s Docker monitoring doesn’t stop with entire containers—it’s also fully capable of monitoring the apps/services running inside those containers. This way, you’ll get more precise metrics for your mission-critical web servers or databases, plus all the pre-configured alarms that come with that collector!
You can monitor specific metrics for any of the 200+ apps/services like MySQL, Nginx, or Postgres, with little or no configuration on your part. Just set the service up using the recommended method, and Netdata will auto-detect it.
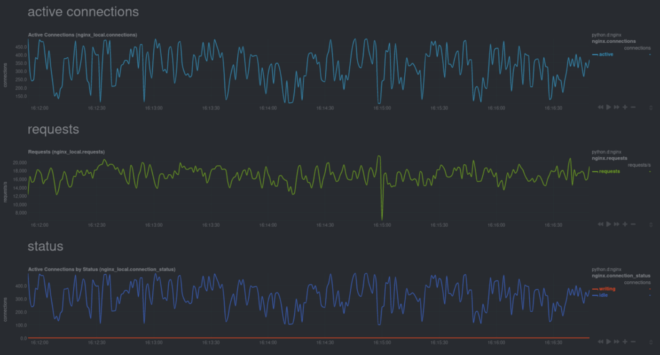
For example, here are some real-time charts for an Nginx web server, running inside of a Docker container, while it’s undergoing a stress test.
Visit our documentation and use the search bar at the top to figure out how to monitor favorite containerized service.
What’s next?
To get started monitoring Docker containers with Netdata, install Netdata on any system running the Docker daemon. Netdata will auto-detect your cgroups and begin monitoring the health and performance of any running Docker containers.
If you already have Netdata installed and want to enable Docker monitoring, restart Netdata using the appropriate command for your system.
Netdata handles ephemeral Docker containers without complaint, so don’t worry about situations where you’re scaling up and down on any given system. As soon as a new container is running, Netdata dynamically attaches all the relevant alarms, and you can see new charts after refreshing the dashboard.
For a more thorough investigation of Netdata’s Docker monitoring capabilities, read our cgroups collector documentation and our Docker Engine documentation. You can also learn about running Netdata inside of a container in your ongoing efforts to containerize everything.
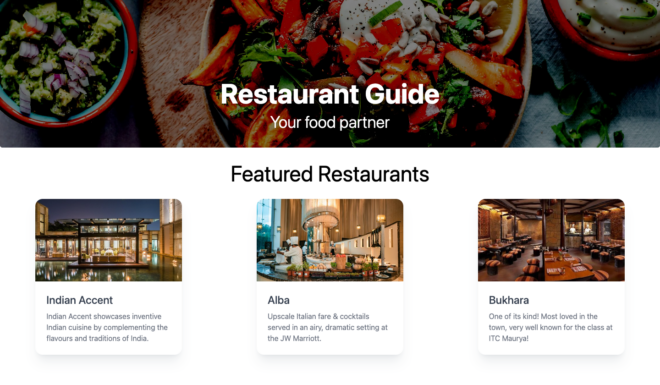
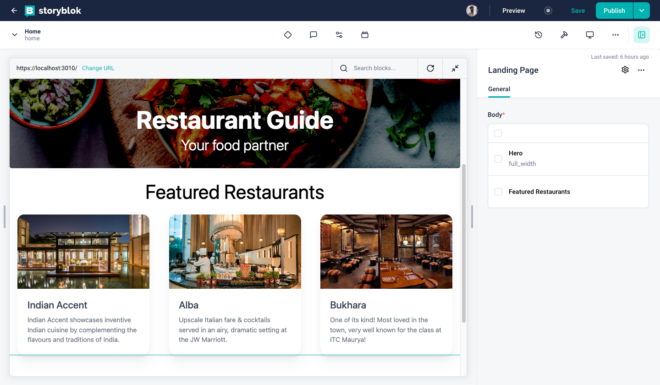
In this tutorial, we will explore how to integrate Next.js with Storyblok along with learning some Next.js and Headless features. We will also see how Storyblok works and enable the live preview of the Storyblok’s Visual Editor. To make things interesting, we will build a Restaurant Guide with the same. Here is a look of what we will be building –
Hint - If you're in a hurry, you can check out the repo at Github. You can also clone the space by clicking here.
Requirements
To follow this tutorial there are the following requirements:
Basic understanding of JavaScript, React and Next.js
Let’s first create a Next.js project by the following command –
npx create-next-app@latest
Feel free to choose your preferences and make sure to add TailwindCSS to the project as the code of this tutorial contains tailwind for styling. Let’s also install the Storyblok React SDK with the following command –
npm i @storyblok/react
The SDK will allow us to interact with the API and enable live editing for us. Let’s now start the development server –
npm run dev
Once the server is started, open your browser at http://localhost:3000. You should see the following screen –
Due the securty reasons, http is not supported inside the Visual Editor of Storyblok, so we need to set up a proxy from an https port to http 3000. You can read more about it in setting up a proxy guide. We will be using 3010 port on https.
Hint - Checkout Storyblok’s Kickstart page to see in detail how to connect Storyblok with any technology, both in a new and existing projects.
Creating a Space in Storyblok
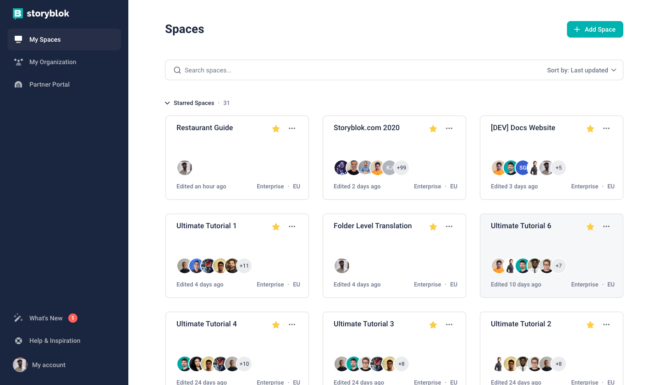
Now, let’s login into the Storyblok App. Once logged in, you will see a list of your spaces. Every card is a space here.
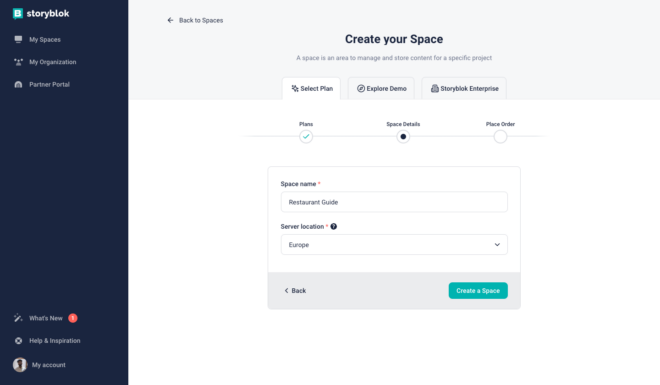
You can consider a space as a content repository, that contains everything like content, users, components, etc. For this tutorial, let’s consider one space as one project. You can read more about spaces in the Structure of Content guide present in the Storyblok website. Let’s now create a new space for our Next.js project by clicking the button present at the right top that says Add Space. Let’s choose creating a New Space from the list of options. There are a couple of plans available to choose from when you create a space. For this tutorial, feel free to choose the Community Plan which is free and requires no payment information.
Then, we can enter the Space name and Server location.
Setting up the Space
Once the space is created, you will see that there is a Home Story created inside the Content section and a couple of blocks (or components) in the Block Library section. We will be creating more stories and blocks according to our requirements of the app. As Storyblok is a headless CMS, you can create stories that are built of different blocks and consume the content inside the stories with the help of APIs on any frontend layer (in this case Next.js)
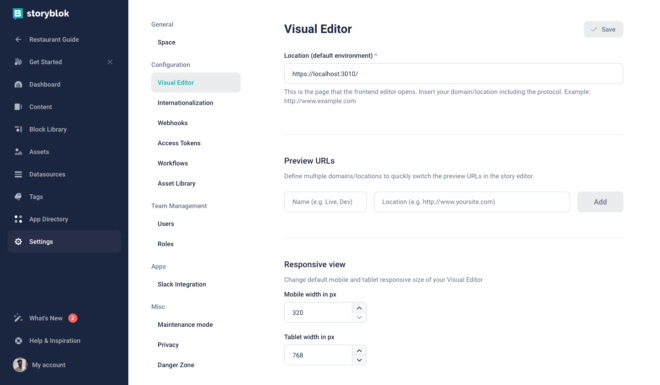
Let’s go to the settings of the space, and then Visual Editor tab. This is the place where you set up the location of the Visual Editor. Let’s change it to https://localhost:3010/ as this is our dev server after the proxy.
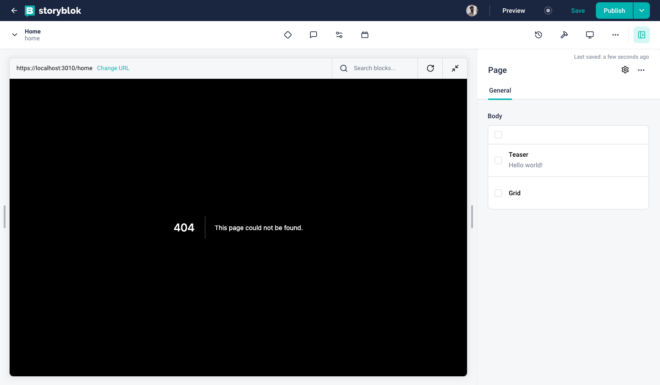
Now let’s go to the home story present inside the Content section, you will see that now we have a our Next.js website there. Though there is a 404, but the aim was to setup the Visual Editor Environment.
Integrating Next.js and Storyblok
Now, let’s add some code to our Next.js project to have the integration with Storyblok working and adding the functionality of live editing. Let’s first delete the page.js file inside the app folder. Then let’s create a [[..slug]] folder and a page.js file inside that. We are doing this to catch all the dynamic routes possible. You can read more about Dynamic Routes in official Next.js docs.
We will add the code to render every route inside this page.js file, let’s first initialize Storyblok. To do so, we need to go to the layout.js file and add storyblokInit function to it. You can add the following –
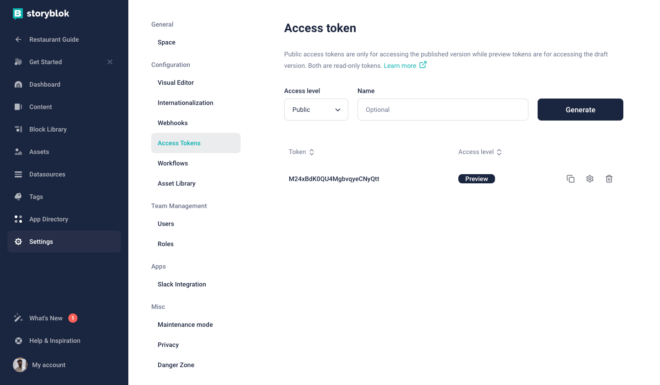
We are importing storyblokInit and apiPlugin from the package, and are initializing the function. You can find the access token of your space inside the settings of the space. Make sure to copy the preview one. You can create more tokens according to the requirements.
apiPlugin helps us to use the functionality of Storyblok JS Client that allows us to interact with the Storyblok API using the SDK. If you don’t want to add it, you can choose your preferred way to fetch the content by making a get request to the Storyblok’s Content Delivery API.
Once this is done, we also need to add a special wrapper component that will allows us to do the edits in real time. As Next.js by default is doing everything on the Server Side with React Server Components, it is not possible to play around with Javascript and listen to such events. Hence, this component will be a Client Side Component.
Create a components folder and then create a new file named StoryblokProvider.js in the components folder. You can paste the following code in that –
/** 1. Tag it as client component */
"use client";
import { storyblokInit, apiPlugin } from "@storyblok/react/rsc";
/** 2. Import your components */
// import Page from "./Page"
/** 3. Initialize it as usual */
storyblokInit({
accessToken: "your-access-token",
use: [apiPlugin],
components: {},
});
export default function StoryblokProvider({ children }) {
return children;
}
Here we do the initalization again on the client side, the previous initialization in the layout will be used to fetch the data. Here, we also have a components key inside the initialization, which will contain all the map of all the components we create for dynamic rendering.
We need to wrap the app inside this component. The layout.js file should now look like this –
import { storyblokInit, apiPlugin} from "@storyblok/react/rsc"
import StoryblokProvider from "@/components/StoryblokProvider"
import './globals.css';
export const metadata = {
title: 'Storyblok and Next.js 14',
description: 'A Next.js and Storyblok app using app router ',
}
storyblokInit({
accessToken: 'your-access-token',
use: [apiPlugin]
})
export default function RootLayout({ children }) {
return (
<StoryblokProvider>
<html lang="en">
<body>{children}</body>
</html>
</StoryblokProvider>
)
}
Now let’s add the logic to the page.js file to render all the routes. Paste the following code inside the file –
import { getStoryblokApi } from "@storyblok/react/rsc";
import StoryblokStory from "@storyblok/react/story";
export default async function Page({ params }) {
let slug = params.slug ? params.slug.join("/") : "home";
const storyblokApi = getStoryblokApi();
let { data } = await storyblokApi.get(
`cdn/stories/${slug}`,
{ version: "draft" },
{ cache: "no-store" }
);
return (
<div className="mb-40">
<StoryblokStory story={data.story} bridgeOptions={{}} />
</div>
);
}
export async function generateStaticParams() {
const storyblokApi = getStoryblokApi();
let { data } = await storyblokApi.get("cdn/links/", {
version: "draft",
});
let paths = [];
Object.keys(data.links).forEach((linkKey) => {
if (data.links[linkKey].is_folder) {
return;
}
const slug = data.links[linkKey].slug;
if (slug == "home") {
return;
}
let splittedSlug = slug.split("/");
paths.push({ slug: splittedSlug });
});
return paths;
}
In this file, we import getStoryblokApi that is used to fetch the data from Storyblok. First thing to see here is the generateStaticParams function here provided by Next.js. This function is used to define the dynamic routes that should statically generate during build time. This is pretty useful for static generation. You can read more about the function in the Next.js Docs.
In this function, we fetch all the links that are inside Storyblok. This means we get all the entries. We are using the links endpoint of the API which gives us the access to all the links so we don’t have to fetch the complete stories. You can take a look at the links endpoing in the API reference. We are ignoring the home slug here, as it will be used for all the other routes along with it.
Once we have all the links we return the paths array as required by generateStaticParams function in the required format. Once we have all the links, the Page function can handle the logic for rendering it. Inside the Page function, we first retrieve the slug and fetch the content of that slug using the API. With the fetch, the first parameter is the slug, second one is the API Options where we define the version in this case (there are more options that can be passed), and the third parameter is to pass custom fetch options.
Storyblok stores two versions of content, one is draft and the other is published. By default, when you create something or make changes, the new content is stored as draft until you hit publish.
Hint - Only Preview token can fetch the draft as well as the published version of content. Public token can only fetch the published version.
We also pass the third parameter as { cache: "no-store" } for Next.js, so that the request is not cached all the time when the content changes.
After we get the data, we use the StoryblokStory component to render the components received in the content dynamically. We also need to pass the story property which will contain the content of the component. The other property is the bridgeOptions, which takes the options for the bridge.
Now with this all done, we are ready to create the new stories and components!
Creating Stories and Components
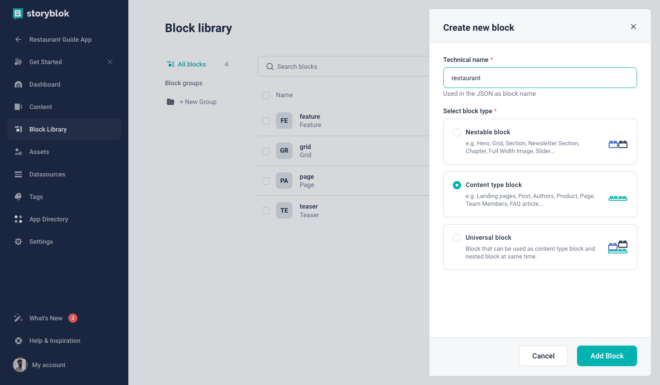
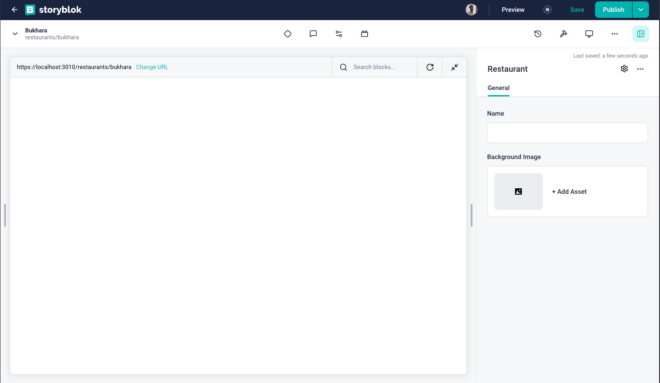
Let’s start by creating a Restaurant component first. This will help us understand the basics, and then we can add multiple fields as well as components. Go to the Block Library in Storyblok, you will see that there are already a few blocks created. We won’t be using these, so let’s create a new one by clicking the button on right top that says Create New . Let’s add the name restaurant for this, and choose Content type block.
There are 3 different types of components in Storyblok, Content type blocks are the ones that can be standalone stories. The Nestable ones are the ones that can be added in other blocks. And, Universal blocks can be used as both.
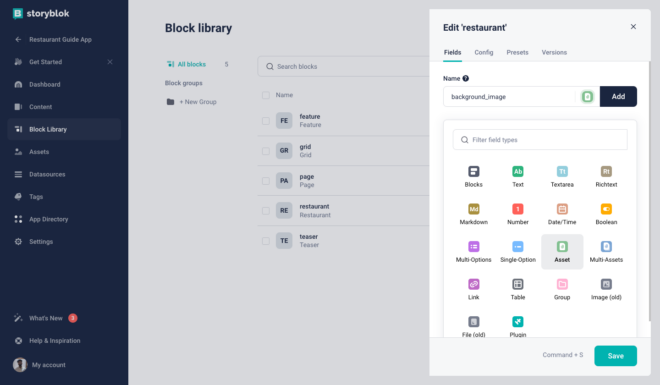
Now once the component is added, we need to add a couple of fields to it. Let’s start by adding a name field and a background image field. The pre selected field type is text, but you can change it while creating the field or after the field is created. For the background_image, select (or change to) the type asset.
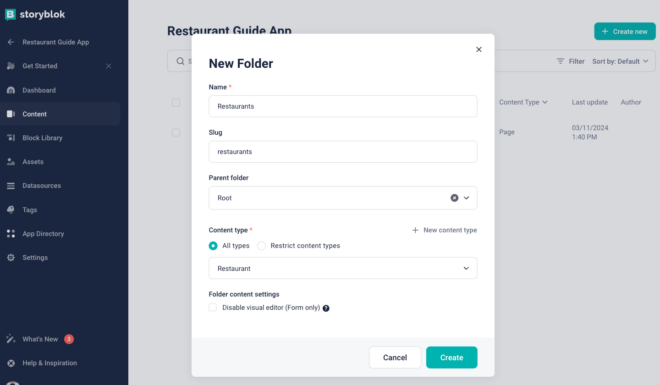
Once the component is created, we can use this to create new Restaurant stories to store the content related to a restaurant. Let’s go the Content section, and add a new folder named Restaurants. This folder will store all the restaurants. Select the default content type as Restaurant.
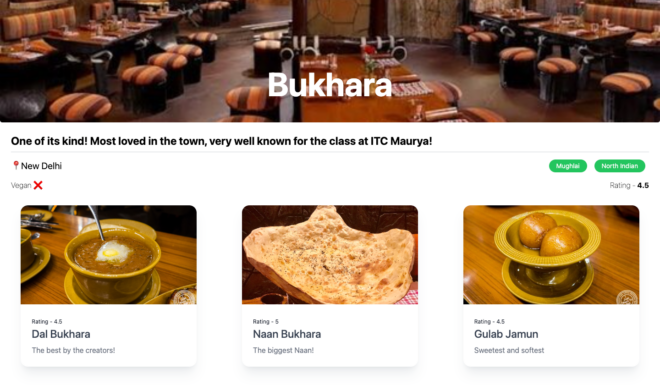
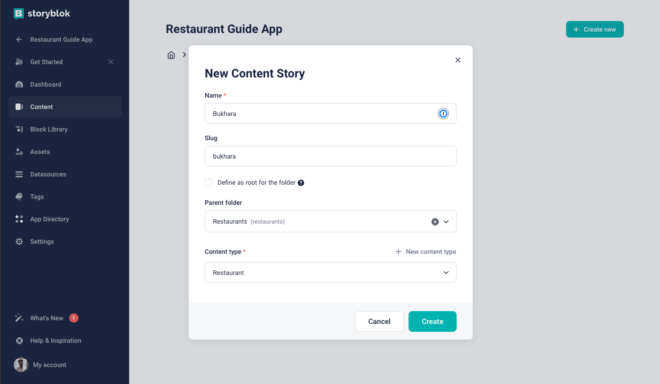
Once the folder is created, add a new story inside it for a restaurant. Feel free to choose the name of the restaurant.
Once the story is created, you will see the fields that we added in our component.
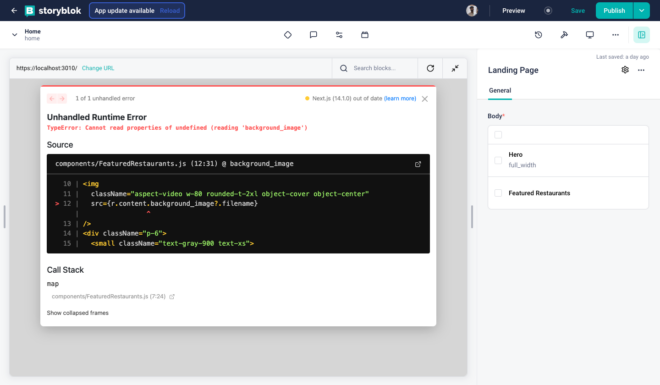
The fields are empty, as well as our frontend is not showing anything at this moment. Add the content to the fields and then let’s hit the save button on the right top. Even when we hit save, nothing is shown in the Visual Editor. This is because we are missing one important step – creation of component on the frontend. You should also see a warning in the terminal saying that the component doesn’t exist.
Let’s now create a Restaurant component in our Next.js project. Create a new file name Restaurant.js inside the components folder and paste the following code –
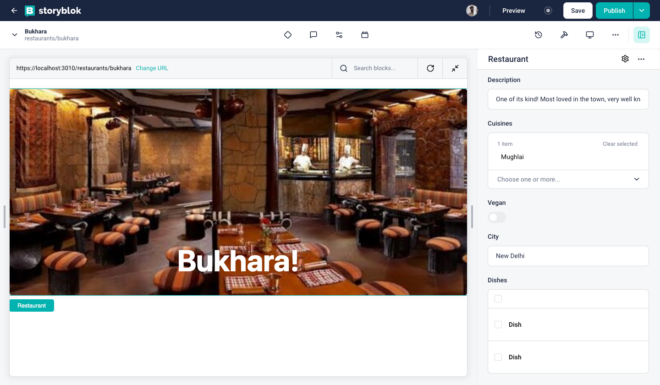
In this component, we are getting a property named blok that we passed from the StoryblokStory as the story property. This blok property will contain all the information coming from the story. In this case, it will have the name we added along with the background_image. We can directly access those properties from the blok object. For the name, it is blok.name and for the image it is blok.background_image?.filename. This is because asset field gives you another object which contains other information along with image’s url under the property name filename.
The components where live editing is required must have the StoryblokEditable function on the root element as we have it here on the main tag. This allows us to see the dotted lines inside the visual editor and makes the components clickable.
Once we save this component, we also need to add this to the initalization in the StoryblokProvider.js file –
/** 1. Tag it as client component */
"use client";
import { storyblokInit, apiPlugin } from "@storyblok/react/rsc";
/** 2. Import your components */
import Restaurant from "./Restaurant";
/** 3. Initialize it as usual */
storyblokInit({
accessToken: "your-access-token",
use: [apiPlugin],
components: {
'restaurant': Restaurant
},
});
export default function StoryblokProvider({ children }) {
return children;
}
As soon as we save this, we should see the preview in the Visual Editor! Now, if you try to change the text or the image, you will even see a live preview in real time. Congratulations, we now have everything working for us. Now it is all about creating new fields and new components.
Let’s now add the following fields (along with the types) to the Restaurant block –
description – Textarea
cuisines – Multi-Options
vegan – Boolean
city – Text
dishes – Blocks
You can add more fields of your choice, once the fields are added we just need to map those in the frontend to be used by our Restaurant component.
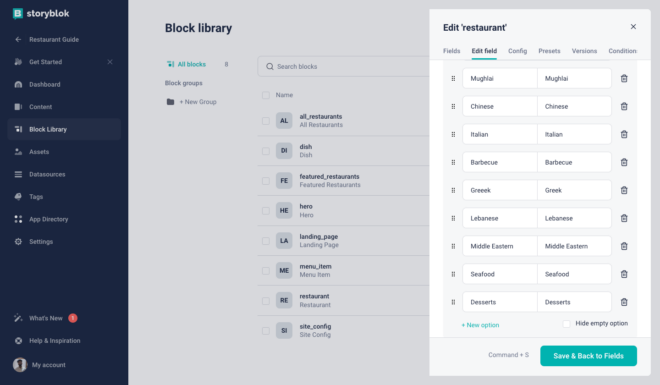
For the cuisines field that we added, you can add options of your choice.
The dishes field that we added is of type blocks. Blocks is a special type that allows other nestable components to be inserted inside it. As it is recommened to be as granular as possible, we can make another component named dish that can be added inside that field.
Let’s add a new nestable block named dish with the following fields –
name – Text
description – Textarea
image – Asset
Let’s now go to the newly added restaurant and fill the other fields along with adding a dish block there.
Now to make all these fields visible, we need to add those in our Restaurant component in Next.js and we also need to add a Dish component in our frontned. Paste the following code in a new file named Dish.js under the components folder –
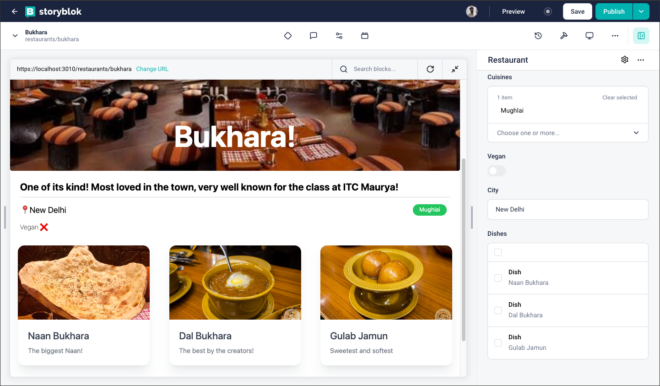
Once this is done, we should be able to see the other fields rendered as well. The best part here is that, whenever you change anything like adding or deleting a new dish, changing the images or text – everything is visible in real time. Feel free to try dragging the components as well to see the power of Visual Editor.
At this point, we have covered all important things and we are ready with our fully functional website. Just to make it better, let’s add a few more restaurants in the folder.
To make our website look good, let’s also make the landing page better as well. Delete the home story that we have, and then go the block library to make some changes and add new blocks. You can go ahead and delete the page block as well. Let’s create the following components now –
landing_page
body – Blocks
hero
headline – Text
subheadline – Text
image – Asset
layout – Single-Option with two options ( constrained and full_width)
featured_restaurants
restaurants – Multi Option
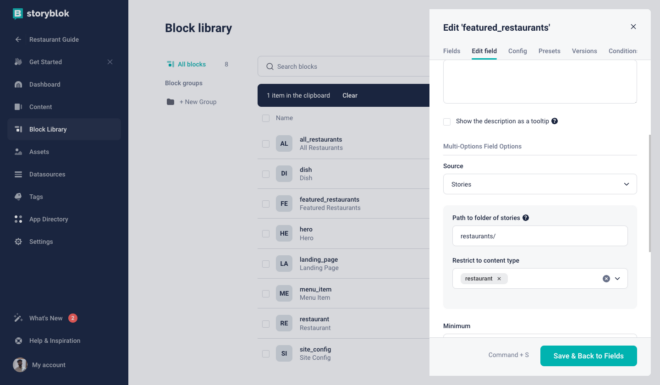
In the restaurant field of featured_restaurants block, change the source to Stories and add the path folder as well as the content type as shown below –
This will allow us to select the restaurants in the block from the Restaurants folder.
Now let’s add the following components to our Next.js project –
The StoryblokComponent here allows us the render the components dynamically and is also used behind the scenes while using the StoryblokStory component.
The final version of StoryblokProvider.js with all the components should like this –
/** 1. Tag it as client component */
"use client";
import { storyblokInit, apiPlugin } from "@storyblok/react/rsc";
/** 2. Import your components */
import FeaturedRestaurants from "./FeaturedRestaurants";
import LandingPage from "./LandingPage";
import Hero from "./Hero";
import Restaurant from "./Restaurant";
/** 3. Initialize it as usual */
storyblokInit({
accessToken: "your-access-token",
use: [apiPlugin],
components: {
restaurant: Restaurant,
hero : Hero,
"landing_page": LandingPage,
"featured_restaurants": FeaturedRestaurants,
},
});
export default function StoryblokProvider({ children }) {
return children;
}
Now let’s go ahead and create a new home story using the landing page block. Add two blocks, the hero and featured_restaurants to its body field. Let’s also add data to these fields along with selecting the restaurants in the Featured Restaurants field. You will see that we get an error here, this is because the restaurants we select aren’t stored as the complete stories but as references. If you try checking the API response, you will see there are just a few UUIDs under the field.
We need to resolve this field to get the data for the restaurants inside the component. For this case, there is a parameter that we can pass named as resolve_relations. We also need to resolve the relations for the bridge.
Resolving Relations(for referencing one story in another story)
In the Page.js file where we fetch the data, we need to add the parameter as mentioned below –
let { data } = await storyblokApi.get(`cdn/stories/${slug}`, {version: 'draft', resolve_relations: ["featured_restaurants.restaurants"]}, {cache: "no-store"});
Also, as mentioned earlier, there is an option for passing the bridge options in the StoryblokStory. To pass that please change the component tag to the following in the same file –
And that is all! The error should be gone now. The preview will display the content rendered the way it should be along with the enabled live editing. We can now make any number of changes, add different blocks and it will all be editable in real time.
Similarly, there can be more new blocks (components) and fields created. This was just a basic app to show the capabilities of Next.js and Headless. There are endless possibilities. Make sure to check out the space mentioned in the hint at the top along with the repository for a few more ideas. You can even try creating a demo space that is available while creating a new space.
Conclusion
In this tutorial, we saw how to integrate Next.js and Storyblok. We saw how to manage and consume content using the API, and how to enable a real-time visual experience using the Visual Editor. We also went through a couple of features that Next.js offers to create great user experiences.
The fictional but prescient Dr. Ian Malcom noted in 1993’s Jurassic Park, “…your scientists were so preoccupied with whether or not they could that they didn’t stop to think if they should.” Generative AI’s rapid expansion due to the increase in size of large language models has felt something akin to genetically engineering a TRex. It is certainly fun and exciting, but what are the consequences?
Hardware is also beefing up those CPUs, GPUs, TPUs (all the PUs really) to support the training and distribution of those models. But just as history, and our favorite science fiction movies, have showed us, there is a cost. Of course, we’re all wary that SkyNet (T) might emerge, (and frankly time will tell), but the more pressing matter is the consumption of electricity and water.
Addressing the AI elephant in the room
At Cisco, we’ve been baking predictive AI into our platforms for years, helping IT operations make insightful, and even proactive, decisions. Across compute, storage, and networking infrastructure, application of predictive AI and observability has been incredibly useful in helping organizations scale and optimize their actual infrastructure usage. With APIs paving the way for multi platform integration, we’re seeing wholesale Day 0 to Day N solutions that help organizations manage usage and more.
What the research says
While these gains are exciting, the underlying machine learning technologies that support predictive AI do not have the same resource needs as Generative AI, which requires new approaches to reducing carbon footprint and overall environmental impacts
Over the last five years or so, researchers at universities like Berkeley and the University of Massachusetts saw past the horizon and started experimenting and proving methods that could be employed to lessen the energy consumption (and carbon footprint) of precursor technologies like natural language processing (NLP) to large language model (LLM). They even go as far as to prescribe both software/algorithm and hardware/infrastructure improvements to alleviate the carbon footprint created by training and using NLP and LLM. Even better, similar activities are underway to measure the impact of AI technology on water usage as well.
But, that’s not the whole story..
As of today, the true nature of AI’s impact on energy consumption is REALLY hard to actually quantify. Article after article tries to dig into the actual effect of using generative AI technologies. The challenge is that the combination of large amounts of variables (what task is being done, how is the data center setup, what processors are being used, etc. etc.) and IP secrecy (there is a LOT of money to be made here) makes reaching a true, tangible answer difficult. Not to mention, there is no way of knowing if those running LLM-based services are employing some of the proven mitigations noted above.
The best any of the current research can come up with is energy usage comparable to an average U.S. home per year to the average mid-size country. That’s an unmanageable range which makes understanding the actual impact and ways to mitigate difficult to identify.
So, it seems, that at least in the short term, newer AI technologies will have an increased impact on energy consumption and water usage to the possible negative detriment of the environment.
Problem solving, the developer way
So how can AI exist in conjunction with sustainability efforts? Ah, that’s the interesting part. AI just may be the answer to its own problems. The problem that I mention above about it being difficult to figure out the impact of AI usage on energy and water consumption is being currently worked on by AI sustainability initiatives.
In theory, the models would then be able to suggest solutions to increased water and electricity consumption. r In a slightly less sophisticated model, predictive AI elements are starting to be used to simply just turn things off. This is the simplest answer: eliminate situations where energy is generated but not actually used– and the really cool thing is AI can help us with that.
In the realm of this technological advancement, developers are bestowed with an extraordinary opportunity to make a real impact for a sustainable future.
Getting involved
Cisco’s Build for Better coding challenge, is open March 14 – April 22, 2024, and invites all Developers to harness their skills in AI, Observability, and Sustainability to make a real-world impact. Learn more and commit your code by Earth Day.
At Developer Nation, our commitment extends beyond just gathering data and insights from the developer community; we believe in giving back and making a positive impact. Through our Donation Program, we support causes that resonate with our mission and values, ensuring that our community’s voice is heard not only in surveys but also in charitable endeavours.
How Does it Work?
For every survey wave conducted, we allocate a portion of our resources to donate to charities chosen by the Developer Nation Community. With each completed survey, we contribute $0.10 towards our donation goal, aiming to reach a minimum of $1,600 or more in total donations!
The 26th Developer Nation Survey
During our 26th Developer Nation global survey, we were thrilled to receive 13,852 qualified responses. This remarkable engagement helped us reach $1,385 in donations, inspiring us to continue giving back to our community in various ways.
Charities Supported in the 26th Survey
In line with our commitment to supporting developer-centric initiatives and other causes valued by our community, we distributed our donations among several deserving charities. Here’s a breakdown of the organizations we supported and the contributions they received based on community votes:
1. FreeCodeCamp
FreeCodeCamp is dedicated to providing free coding education to individuals worldwide. With 5,197 (out of 13,852) survey participants showing their support, we were able to donate $520 to further their mission of making coding accessible to everyone.
2. Mozilla Foundation
The Mozilla Foundation champions an open and accessible internet for all, promoting privacy, security, and digital literacy. With 2,997 votes from our community, we contributed $300 to advance their mission of a healthier internet ecosystem.
3. Engineers Without Borders
Engineers Without Borders (EWB) harnesses the skills of engineers to address global challenges, from clean water access to sustainable infrastructure. Supported by 2,584 out of 13,852 survey participants, we donated $258 to support their impactful projects worldwide.
4. Ada Developers Academy
Ada Developers Academy is dedicated to increasing diversity in tech by providing women and gender-diverse individuals with comprehensive software development training. With 1,759 votes from our community, we contributed $176 to empower more individuals with the skills and opportunities they need to thrive in tech.
5. ADRA (Adventist Development and Relief Agency)
ADRA works tirelessly to address social injustice and provide humanitarian aid to communities in need worldwide. With 1,209 votes from our community, we donated $121 to support their efforts in promoting sustainable development, disaster relief, and advocacy.
Conclusion: Fostering Community and Social Responsibility
At Developer Nation, we believe that giving back to society is integral to our mission. We extend our deepest gratitude to our community members for their enthusiastic participation in our Donation Program. Your contributions have not only exceeded our expectations but also reaffirmed our collective commitment to making a difference.
As we continue our journey, we welcome your thoughts and suggestions for future donations. Your feedback plays a crucial role in shaping our philanthropic efforts, ensuring that we remain aligned with the causes that matter most to you.
Join us in our mission to build a brighter, more inclusive future through technology and compassion. Together, we can make a meaningful impact on the world!
This episode explores the exciting world of Enterprise IoT with Kudzai Manditereza, a Developer Advocate at HiveMQ. Ayan and Kudzai delve into three key areas:
Enterprise IoT Development: They discuss the unique challenges and opportunities associated with developing and implementing IoT solutions for businesses. This involves exploring various technologies, platforms, and considerations specific to enterprise-grade deployments.
Digital Transformation Across Industries: Kudzai sheds light on how digitization is transforming various industries, from manufacturing and healthcare to logistics and retail. He shared how companies are leveraging IoT to improve efficiency, gain real-time insights, and create innovative products and services.
Kudzai’s Role and MQTT: Ayan and Kudzai explore Kudzai’s role in helping traditional companies navigate their digital transformation journeys and adopt IoT solutions. They discussed how Kudzai leverages his expertise to bridge the gap between traditional business models and the possibilities of IoT. The conversation also touched upon the role of MQTT, a popular messaging protocol, in enabling communication and data exchange within IoT ecosystems.
This episode offers valuable insights for businesses considering or embarking on their IoT journeys. By listening to Kudzai’s expertise and Ayan’s engaging discussion, listeners can gain a better understanding of the potential of Enterprise IoT, its impact across industries, and how it can be leveraged for business growth and innovation.
In this captivating episode, we delve into the dynamic journey of Anand Mishra, the CTO of Analytics Vidhya, a frontrunner in the Data Science realm. Anand shares his transformative evolution from a Data Scientist to assuming the pivotal role of CTO, illuminating the intricate pathways and milestones that shaped his career trajectory. As we navigate through his experiences, listeners gain invaluable insights into the evolving landscape of Data Science, particularly amidst the burgeoning influence of AI.
Anand provides a compelling narrative on where the field of Data Science is headed, painting a vivid picture of its metamorphosis under the relentless march of artificial intelligence. From the intricate nuances of modern data analytics to the potential unleashed by generative AI, Anand’s perspective offers a glimpse into the future of this rapidly evolving domain.
With each anecdote and observation, Anand weaves a narrative that not only captures the essence of his personal journey but also serves as a compass for those navigating the ever-changing seas of Data Science and AI. Join us as we unravel the tapestry of innovation and exploration in this thought-provoking conversation with one of the foremost voices in the field.
Tune in to uncover the untold stories, gain exclusive insights, and embark on a journey of discovery that promises to illuminate the path ahead in the enthralling world of Data Science and AI.