Rarely any software project today is built from the ground up. Frameworks and libraries have made developers’ lives so easy that there’s no need to reinvent the wheel anymore when it comes to software development. But these frameworks and libraries become dependencies of our projects, and as the software grows in complexity over time, it can become pretty challenging to efficiently manage these dependencies.
Sooner than later developers can find their code depending on software projects of other developers which are either open source, hosted online or being developed in-house, in maybe another department of the organisation. These dependencies are also evolving, and need to be updated and in sync with your main source tree. This ensures that a small change breaks nothing and your project is not outdated and does not have any known security vulnerability or bugs.
A good recent example of this is log4j, a popular framework for logging, initially released in 1999, which became a huge headache for many businesses at the end of 2021, including Apple, Microsoft and VMware. log4jt was a dependency in a variety of software and the vulnerabilities discovered affected all of them. This is a classic example of how dependencies play a huge role in software lifecycle and why managing them efficiently becomes important.
While there are a variety of ways and frameworks to manage software dependencies, depending on software complexity, today I’ll cover one of the most common and easy to use methods called “git submodule”:. As the name suggests it is built right into git itself, which is the de facto version control system for the majority of software projects.
Hands-on with git submodules:
Let us assume your project name “hello-world” depends on an open source library called “print”.
A not-so-great way to manage the project is to clone the “print” library code and push it alongside the “Hello World” code tree to GitHub (or any version control server). This works and everything runs as expected. But what happens when the author of “print” makes some changes to its code or fixes a bug?Since you’ve used your own local copy of print and there is no tracking to the upstream project, you won’t be able to get these new changes in, therefore you need to manually patch it yourself or re-fetch and push the code once again. Is this the best way of doing it, one may ask?
git has this feature baked in which allows you to add other git repos (dependencies projects) as submodules. This means your project will follow a modular approach and you can update the submodules, independent of your main project. You can add as many submodules in your project as you want and assign rules such as “where to fetch it from” and “where to store the code once it is fetched”. This obviously works if you use git for your software project version control.
Let’s see this in action:
So I’ve created a new git project namely “hello-world” on my GitHub account, which has two directories:
src – where my main source code is stored
lib – where all the libraries a.k.a dependencies are stored which my source code is using.
These libraries are hosted on GitHub by their maintainers as independent projects. For this example, I’m using two libraries.
hello – which is also created by me as a separate github repo
resources – which is another git repository in Developer Nation account
To add these two above-mentioned libraries as submodules to my project, let’s open the terminal, change to the main project directory where I want them to be located. In this case, I want them in my lib directory, so I’ll execute the following commands:
cd hello-world/lib
Add submodule with command : git submodule add <link to repo>
This will fetch the source code of these libraries and save them in your lib folder. Also, now you’ll find a new hidden file created in root of your main project directory with name .gitmodules which has the following meta-data:
Now every time someone clones the project, they can separately clone the submodule using following commands:
git clone < Your project URL >
cd <Your project URL>
git submodule init
git submodule update
OR:
This can also be done in one command as:
git clone <Your Project URL> —recursive, in this case
git clone git@github.com:iayanpahwa/hello-world.git —recursive
One more thing you’ll notice on GitHub project repo is in lib directory, folders are named as :
print @ fa3f …
resources @ c22
The hash after @ denotes the last commit from where print and resources libraries were fetched. This is a very powerful feature as by default, the submodule will be fetched from the latest commit available upstream i.e HEAD of master branch, but you can fetch from different branches as well. More details and options can be found on the official doc here.
Now you can track and update dependency projects independent of your main source tree. One thing to note is all your dependencies need not to be on the same hosting site as long as they’re using git. For example: If hello-world was hosted on Github and printed on Gitlab, the git submodule will still work the same.
I hope this was a useful tutorial and you can now leverage git submodules to better manage your project dependencies. If you have any questions and ideas for more blogs, I’d love to hear from you in the comments below.
If you ever wondered how game designers come up with placement and immersability of assets such as health meter and mission progress without them hindering game play, this article is for you. Like websites or mobile apps, video games have common UI components that help players navigate and accomplish goals. In this article you’ll discover the four classes of game UI and how as a game designer you can utilise them to provide for the best possible gaming experience.
Sixty years ago the Brookhaven National Laboratory in Upton, NY held an open house. Visitors who toured the lab were treated to an interactive exhibit, a game titled Tennis for Two. The setup was simple—a 5-inch analog display and two controllers, each with one knob and one button. The world’s first video game was born, but after two years, the exhibit was closed.
Twelve years passed, and an eerily similar arcade game showed up in a bar called Andy Capp’s Tavern. The name of the game? Pong. Its maker? Atari. Seemingly overnight, the burgeoning world of video games was transformed. Novelty became an industry.
Since Pong, the complexity of video game graphics has evolved exponentially. We’ve encountered alien insects, elven adventures, and soldiers from every army imaginable. We’ve braved mushroom kingdoms, boxing rings, and an expanding universe of hostile landscapes. While it’s fun to reminisce about the kooky characters and impossible plot lines, it’s also worth discussing the design elements that make video games worth playing—the UI components.
Like websites or mobile apps, video games have common UI components that help players navigate, find information, and accomplish goals. From start screens to coin counters, video game UI components are a crucial aspect of playability (a player’s experience of enjoyment and entertainment). To understand how these components impact the gaming experience, we must quickly address two concepts that are vital to video game design: Narrative and The Fourth Wall.
Narrative
Narrative is the story that a video game tells. Consider this as your video game character storyline.
The Fourth Wall
The Fourth Wall is an imaginary barrier between the game player and the space in which the game takes place.
Narrative and The Fourth Wall provide two questions that must be asked of every UI component incorporated into a game:
Does the component exist in the game story?
Does the component exist in the game space?
From these two questions, four classes of video game UI components emerge: Non-diegetic; Diegetic; Spatial; and Meta.
Non-Diegetic
Does the component exist in the game story? No
Does the component exist in the game space? No
Non-diegetic UI components reside outside of a game’s story and space. None of the characters in the game, including a player’s avatar, are aware that the components exist. The design, placement, and context of non-diegetic components are paramount.
In fast-paced games, non-diegetic components may interrupt a player’s sense of immersion. But in strategy-heavy games, they can provide players with a more nuanced assessment of resources and actions.
Non-Diegetic components commonly appear in video games as stat meters. They keep track of points, time, damage, and various resources that players amass and expend during gameplay.
In Super Mario Bros. 3, the stat meter is non-diegetic because it exists outside of the game world and story (characters within the game don’t know it’s there).
Diegetic
Does the component exist in the game story? Yes
Does the component exist in the game space? Yes
Diegetic UI components inhabit both a game’s story and space, and characters within the game are aware of the components. Even though they exist within the game story and space, poorly considered diegetic components are still capable of distracting or frustrating players.
Scale makes diegetic components tricky. For instance, an in-game speedometer that resides on a vehicle’s dashboard will likely be too small for players to see clearly. In some games, handheld diegetic components (like maps) can be toggled to a 2-D, full-screen view, making them non-diegetic.
In the demolition racing game Wreckfest, cars are diegetic UI components. Over the course of a race, they take on visible damage that indicates how near a player is to being knocked out of competition.
Spatial
Does the component exist in the game story? No
Does the component exist in the game space? Yes
Spatial UI components are found in a game’s space, but characters within the game don’t see them. Spatial components often work as visual aids, helping players select objects or pointing out important landmarks.
Text labels are a classic example of spatial UI components. In fantasy and adventure games, players may encounter important objects that are unfamiliar in appearance. Text labels quickly remove ambiguity and keep players immersed in the gaming experience.
The American football franchise Madden has spatial UI components that help players select avatars and understand game scenarios.
Meta
Does the component exist in the game story? Yes
Does the component exist in the game space? No
Meta UI components exist in a game’s story, but they don’t reside in the game’s space. A player’s avatar may or may not be aware of meta components. Traditionally, meta components have been used to signify damage to a player’s avatar.
Meta components can be quite subtle—like a slowly accumulating layer of dirt on the game’s 2D plane, but they can also feature prominently in the gaming experience. In action and adventure games, the entire field of view is sometimes shaken, blurred, or discolored to show that a player has taken on damage.
The Legend of Zelda utilizes scrolling text (a meta component) to advance the narrative and provide players with helpful tips.
A very illustrative infographic summing up all 4 classes of video game UI components can be found below.
Classifying video game UI components isn’t always cut and dry. A life meter may be diegetic in one game but non-diegetic in another. Depending on a game’s narrative and its players’ relationship to the fourth wall, components may blur the line between classes. Likewise, an infinite range of visual styles and configurations can be applied to components according to a game’s art direction.
Software development is a messy and intensive process, which in theory, should be a linear, cumulative construction of functionalities and improvements in code, but is rather more complex. More often than not it is a series of intertwined, non-linear threads of complex code, partly finished features, old legacy methods, collections of TODO comments, and other things common to any human-driven and a largely hand-crafted process known to mankind.
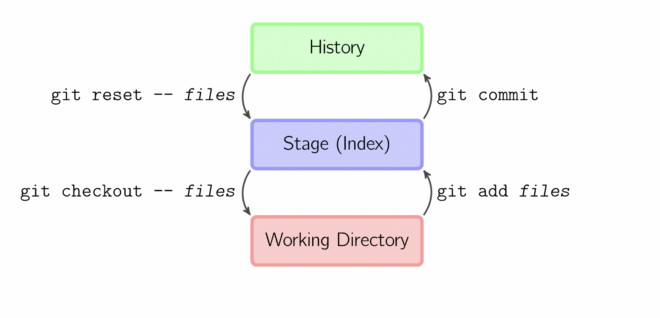
Git was built to make our lives easier when dealing with this messy and complex approach to software development. Git made it possible to work effortlessly on many features at once and decide what you want to stage and commit to the repository. The staging area in Git is the main working area, but most of the developers know only a little about it.
In this article, we will be discussing the staging area in Git and how it is a fundamental part of version control and can be used effectively to make version control easier and uncomplicated.
What is Staging area?
To understand what is staging area is, let’s take a real-world example – suppose that you are moving to another place, and you have to pack your stuff into boxes and you wouldn’t want to mix the items meant for the bathroom, kitchen, bedroom, and the living room in the same box. So, you will take a box and start putting stuff into it, and if doesn’t make sense, you can also remove it before finally packing the box and labeling it.
Here, in this example, the box serves as the staging area, where you are doing the work (crafting your commit), whereas when you are done, then you are packing it and labeling it (committing the code).
In technical terms, the staging area is the middle ground between what you have done to your files (also known as the working directory) and what you had last committed (the HEAD commit). As the name implies, the staging area gives you space to prepare (stage) the changes that will be reflected on the next commit. This surely adds up some complexity to the process, but it also adds more flexibility to selectively prepare the commits as they can be modified several times in the staging area before committing.
Assume you’re working on two files, but only one is ready to commit. You don’t want to be forced to commit both files, but only the one that is ready. This is where Git’s staging area comes in handy. We place files in a staging area before committing what has been staged. Even the deletion of a file must be recorded in Git’s history, therefore deleted files must be staged before being committed.
What are git commands for the staging area?
git add
The command used to stage any change in Git is git add. The git add command adds a modification to the staging area from the working directory. It informs Git that you wish to include changes to a specific file in the next commit. However, git add has little effect on the repository—changes are not truly recorded until you execute git commit.
The common options available along with this command are as follows:
You can specify a <file> from which all changes will be staged. The syntax would be as follows:
git add <file>
Similarly, you can specify a <directory> for the next commit:
git add <directory>
You can also use a . to add all the changes from the present directory, such as the following:
git add .
git status
git status command is used to check the status of the files (untracked, modified, or deleted) in the present branch. It can be simply used as follows:
git status
git reset
In case, you have accidentally staged a file or directory and want to undo it or unstage it, then you can use git reset command. It can be used as follows:
git reset HEAD example.html
git rm
If you remove files, they will appear as deleted in git status, and you must use git add to stage them. Another option is to use the git rm command, which deletes and stages files in a single command:
To remove a file (and stage it)
git rm example.html
To remove a folder (and stage it)
git rm -r myfolder
git commit
The git commit command saves a snapshot of the current staged changes in the project. Committed snapshots are “secure” versions of a project that Git will never alter unless you specifically ask it to.
Git may be considered a timeline management utility at a high level. Commits are the fundamental building blocks of a Git project timeline. Commits may be thought of as snapshots or milestones along a Git project’s history. Commits are produced with the git commit command to record the current status of a project.
Git Snapshots are never committed to the remote repository. As the staging area serves as a wall between the working directory and the project history, each developer’s local repository serves as a wall between their contributions and the central repository.
The most common syntax followed to create a commit in git is as follows:
git commit -m "commit message"
The above commands and their functionalities can be summed up simply in the following image:
Conclusion
To summarize, git add is the first command in a series of commands that instructs Git to “store” a snapshot of the current project state into the commit history. When used alone, git add moves pending changes from the working directory to the staging area. The git status command examines the repository’s current state and can be used to confirm a git add promotion. To undo a git add, use the git reset command. The git commit command is then used to add a snapshot of the staging directory to the commit history of the repository.
This is all for this article, we will discuss more Git Internals in the next article. Do let me know if you have any feedback or suggestions for this series.
If you want to read what we discussed in the earlier instalments of the series, you can find them below.
Git Internals Part 1- List of basic Concepts That Power your .git Directory here
Git Internals Part 2: How does Git store your data? here
Code reviews are a type of software quality assurance activity that involves rigorous evaluations of code in order to identify bugs, improve code quality, and assist engineers in understanding the source code.
Implementing a systematic approach for human code reviews is one of the most effective ways to enhance software quality and security. Given the probability of mistakes during code authorship, using many fresh eyes with complementary knowledge may disclose flaws that the original programmer may have overlooked.
A successful peer review process requires a careful balance of well-established protocols and a non-threatening, collaborative atmosphere. Highly structured peer evaluations can hinder productivity, while lax approaches are frequently unsuccessful. Managers must find a happy medium that allows for fast and successful peer review while also encouraging open communication and information sharing among coworkers.
The Benefit/Importance of Code Reviews
The fundamental goal of code review is to guarantee that the codebase’s code health improves with time.
Code health is a “concept” used to measure if the codebase on which one or more developers are working is — manageable, readable, stable (or less error-prone), buildable, and testable.
Code reviews enhance code quality by detecting issues before they turn unmanageable, it ensures a consistent design and implementation and also assures consistency of standards. It contributes to the software’s maintainability and lifespan, resulting in sturdy software created from components for smooth integration and functioning. It is inevitable that adjustments will be required in the future, thus it is critical to consider who will be accountable for implementing such changes.
When source code is regularly reviewed, developers can learn dependable techniques and best practices, as well as provide better documentation, because some developers may be oblivious of optimization approaches that could be applicable to their code. The code review process allows these engineers to learn new skills and improve the efficiency of their code, and produce better software.
Another significant benefit of code reviews is that they make it easier for analysts and testers to comprehend. In Quality Assurance (QA) testing, testers must not only evaluate the code quality but also discover issues that contribute to bad test results. This can result in ongoing, needless development delays owing to further testing and rewriting.
Performing Code Reviews
Good code reviews should be the standard that we all strive towards. Here are some guidelines for establishing a successful code review to ensure high-quality and helpful reviews in the long run:
Use checklists
Every member of your team is quite likely to repeat the same mistakes because omissions are the most difficult to identify since it is hard to evaluate something that does not exist. Checklists are the most effective method for avoiding frequent errors and overcoming the challenges of omission detection. Checklists for code reviews can help team members understand the expectations for each type of review and can be beneficial for reporting and process development.
Set limits for review time and code lines checked
It might of course be very much tempting to rush through a review and expect someone else to detect the mistakes you omitted. However, a SmartBear study indicates a considerable decline in defect density at speeds quicker than 500 LOC per hour. The most effective code review is performed in a suitable quantity, at a slower speed, for a limited period of time.
Code review is vital, but it can also be a time-consuming as well as a painstaking process. As a result, it is critical to control how much time a reviewer or team spends on the specifics of each line of code. Best practices in this area include ensuring that team members do not spend more than an hour on code reviews and that the team does not examine more than a few hundred lines in a certain amount of hours.
In essence, it is strongly advised not to review for more than 60 minutes at a time, as studies suggest that taking pauses from a task over time can significantly increase work quality. More regular evaluations should lessen the need for a review of this length in the future.
Performing a security code review.
A security code review is a manual or automated method that assesses an application’s source code. Manual reviews examine the code’s style, intent, and functional output, whereas automated tools check for spacing or name errors and compare it to known standard functions. A security code review, the third sort of evaluation, examines the developer’s code for security resilience.
The goal of this examination is to identify any current security weaknesses or vulnerabilities. Among other things, code review searches for logic flaws, reviews spec implementation, and verifies style guidelines. However, it is also important that a developer should be able to write code in an environment that protects it against external attacks, that can have effects on everything from intellectual property theft to revenue loss to data loss. Limiting code access, ensuring robust encryption, and establishing Secrets Management to safeguard passwords and hardcodes from widespread dissemination are some examples.
Make sure pull requests are minimal and serve a single function.
Pull requests (PRs) are a typical way of requesting peer code evaluations. The PR triggered the review process when a developer completes an initial code modification. To improve the effectiveness and speed of manual code review, the developer should submit PRs with precise instructions for reviewers. The lengthier the review, the greater the danger that the reviewer may overlook the fundamental goal of the PR. In fact, a PR should be no more than 250 lines long because a study shows reviewers may find 70–90 percent of errors in under an hour.
Offer constructive feedback.
Giving constructive feedback are very essential as code reviews play very important roles in software development, however, it is also important to be constructive rather than critical or harsh in your feedback to maintain your team’s morale and ensure keep the team learns from the mistake.
Code review examples
The main outcome of a code review process is to increase efficiency. While these traditional methods of code review have worked in the past, you may be losing efficiency if you haven’t switched to a code review tool. A code review tool automates the process of code review so that a reviewer solely focuses on the code.
A code review tool integrates with your development cycle to initiate a code review before new code is merged into the main codebase. You can choose a tool that is compatible with your technology stack to seamlessly integrate it into your workflow.
A great example of code review, especially in Python, which is my favored language, would be dealing with Duck Typing, which is strongly recommended in Python to be more productive and adaptable. Emulating built-in Python types such as containers is a common use-case:
Full container protocol emulation involves the presence and effective implementation of several magic methods. This can become time-consuming and error-prone. A preferable approach is to build user containers on top of a respective abstract base class:
# Extra Pythonic!
class DictLikeType(collections.abc.MutableMapping):
def __init__(self, *args, **kwargs):
self.store = dict(*args, **kwargs)
def __getitem__(self, key):
return self.store[key]
...
We would not only have to implement fewer magic methods, but the ABC harness would also verify that all necessary protocol methods were in place. This mitigates some of the inherent instability of dynamic typing.
Top code review tools for Developers
The fundamental purpose of a code review process, as described earlier in this article, is to enhance efficiency. While the traditional code review approaches outlined above have worked in the past (and continue to work), you may be losing efficiency if you haven’t switched to using a code review tool. A code review tool automates the code review process, freeing up the reviewer’s time to concentrate solely on the code.
Before adding new code to the main codebase, code review tools interact with your development cycle to initiate a code review. You should choose a tool that is compatible with your technological stack so that it can be readily integrated into your workflow. Here is a list of some of the top code review tools:
1. Github You may have previously used forks and pull requests to evaluate code if you use GitHub to manage your Git repositories in the cloud.
Github also stands out due to it’s discussion feature during a pull request, with github you can analyze the difference, comment inline, and view the history of changes. You can also use the code review tool to resolve small Git conflicts through the web interface. To establish a more thorough procedure, GitHub even allows you to integrate with other review tools via its marketplace.
Atlassian’s Crucible is a collaborative code review tool that lets you to examine code, discuss plan modifications, and find bugs across a variety of version control systems.
Crucible integrates well with other products in Atlassian’s ecosystem, including Confluence and Enterprise BitBucket. And, just like with any product that is encircled by other products in its ecosystem, combining Crucible with Jira, Atlassian’s Issue, and Project Tracker, will provide the greatest advantage. It allows you to do code reviews and audits on merged code prior to committing.
SmartBear Collaborator is a peer code and document review tool for development teams working on high-quality code projects. Collaborator allows teams to review design documents in addition to source code.
You can use Collaborator to see code changes, identify defects, and make comments on specific lines of code. You can also set review rules and automatic notifications to ensure that reviews are completed on time. It also allows for easy integration with multiple SCMs and IDEs such as Visual Studio and Eclipse amongst others.
4. Visual Expert
Visual Expert is an enterprise solution for code review specializing in database code. It has support for three platforms only: PowerBuilder, SQL Server, and Oracle PL/SQL. If you are using any other DBMS, you will not be able to integrate Visual Expert for code review.
Visual Expert spares no line of code from rigorous testing. The code review tool delivers a comprehensive analysis of code gathered from a customer’s preferred platform.
5. RhodeCode Rhodecode is a secured, open-source enterprise source code management tool. It is a unified tool for Git, Subversion, and Mercurial. Its primary functions are team collaboration, repository management, and code security and authentication.
Source — Rhodecode
RhodeCode distinguishes itself by allowing teams to synchronize their work through commit code commentary, live code discussions, and sharing code snippets. Teams may also use coding tools to assign review jobs to the appropriate person, resulting in a more frictionless workflow for teams.
Conclusion
We learned what code review is and why it is crucial in the software life cycle in this tutorial. We also discussed best practices for reviewing code and the various approaches for doing so, as well as an example of a code review and lists of top code review tools to assist you get started reviewing code throughout your organization or team.
AWS Lambda is a powerful tool for developing serverless applications and on-demand workflows. However, this power comes at a cost in terms of flexibility and ease of deployment, as the manual deployment process that AWS Lambda recommends can be error-prone and hard to scale.
CloudFormation revolutionizes this process, replacing copied zip files with dependable and repeatable template-based deployment schemes. With CloudFormation, your Lambda functions will be easier to maintain, easier for your developers to understand, and easier to scale as your application grows.
Reviewing AWS Lambda Deployments
AWS Lambda function deployments are based around file handling—namely, by zipping your code into an archive and uploading the file to AWS. At its core, all AWS Lambda functions follow this pattern:
Create a zip file.
Upload to an S3 bucket.
Set the function to active.
This takes place whether you’re manually deploying the code, have outsourced your deployments to a tool, or are following any protocol in-between.
Once the file is received, AWS unzips your code into the appropriate folder structure, making it available to run when the Lambda container is spun up. This approach is a key point to remember as we discuss Lambda deployments and also exposes one of the first holes in the manual deployment process—AWS Lambda functions have an unstated structure that you need to follow.
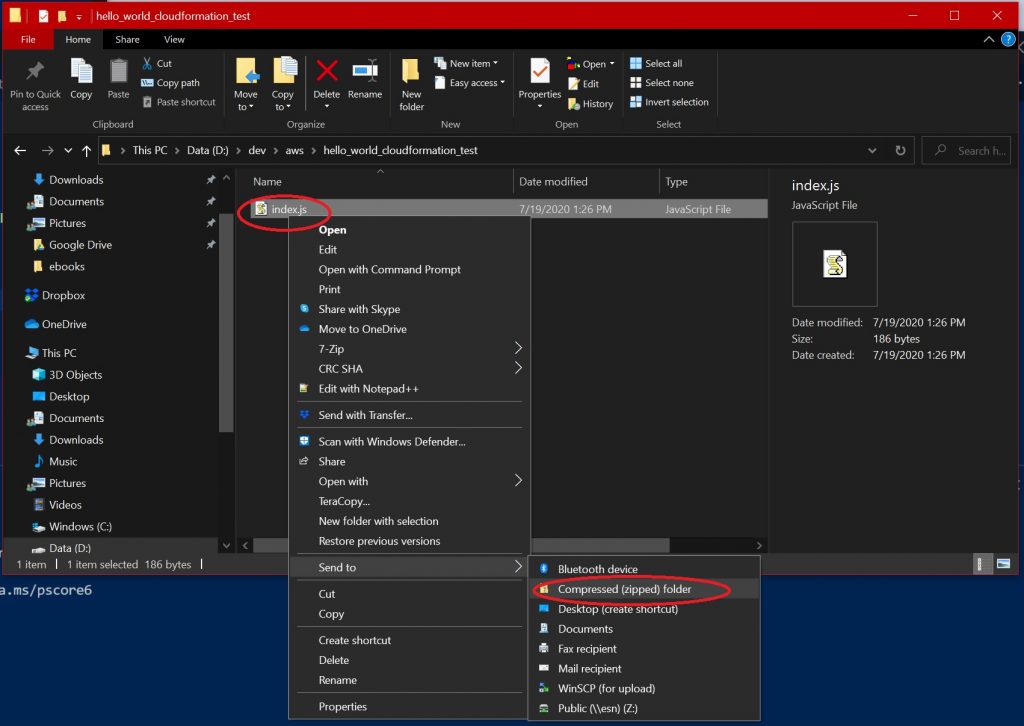
Simply put, you do not want to right-click on a file and create an archive; otherwise, you’ll encounter an error when you try to run your deployed Lambda code. The following screenshots illustrate this issue:
Figure 1: Do not zip the folder using this method
If you examine the zip files produced by the above method, you’ll find that their root level consists of your code folder:
Figure 2: This zip file will not be parsable by AWS Lambda
The issue this introduces is specifically related to how AWS Lambda deploys the code—namely, it simply unzips the provided code archive to an executable folder, then routes invocation requests to the application code found in that folder. When you provide a zip archive with a folder at the root level, instead of the application code itself, AWS Lambda has no idea what to do and throws errors. So, make sure that you zip the folder contents themselves, as follows:
Figure 3: Zipped at the appropriate level, the function code should be the root of the archive
When you do this, your code is put at the root level of the zip folder. This allows AWS Lambda to easily deploy your published code:
Figure 4: The code file is present at the root of the zip archive
IOD recruits tech experts from around the world to create compelling content for our clients’ tech blogs. Contact us to learn how we can help you with your content marketing challenges.
Each Lambda function exists independently, meaning that you cannot easily share resources between Lambda functions—shared libraries, source data files, and all other information sources that need to be included with the zip archive you upload. This additional fragility and duplication can be resolved with Lambda layers. Lambda layers provide you with a common base for your functions, letting you easily deploy shared libraries without the duplication that would be required when using only the base container.
While you can set up a scriptable and maintainable deployment process, once the project size grows, the brittleness of the above steps will quickly become apparent. AWS CloudFormation solves this very complex problem by categorizing infrastructure as code; this lets your developers and development operations teams create, deploy, and tear down resources with simple configuration-file modifications. These configuration files are human-readable and can be modified in any text configuration, programming language, or UI tools that you desire.
Furthermore, CloudFormation lets you centralize the deployment of your infrastructure, creating a build process for your serverless functions that is both repeatable and predictable.
Improving Lambda Deployments with CloudFormation
Moving from the error-prone manual process of Lambda deployment to the superpowered CloudFormation model is a straightforward process of translating your function’s infrastructure needs into the appropriate CloudFormation template language. CloudFormation lets you then consolidate the disparate resource deployments for your application into a small set of configuration files, allowing your infrastructure to be maintained alongside your application code.
All in all, CloudFormation makes deploying AWS Lambda functions incredibly simple.
Start by creating the template file that will define your resources. This will be your working folder for your code. Next, create your function in the appropriate file for your desired Lambda runtime. Finally, create an S3 bucket and provide its address to your Lambda function; once you’ve done this, you can deploy functions simply by copying your zip file to the correct S3 bucket.
CloudFormation will be the tool that ties together all the resources your function requires. In CloudFormation, you will define the function, the function’s IAM role, the function’s code repository in S3, and execution policies to ensure that your function can do everything it needs to do within the AWS ecosystem. CloudFormation further gathers these resources together, centralizing all of your infrastructure definitions in a single template file that lives alongside your code.
Running Through a Sample Deployment
In this section, we’ll run through a quick example of creating a CloudFormation-driven deployment process for an AWS Lambda function. Start with the following Node.JS code to create a simple Lambda function using the nodejs12.x runtime:
This code is deliberately simple, allowing you to highlight the deployment process itself. Once you’ve created the function code, you can begin creating all of the items that will allow you to deploy and run the code with CloudFormation.
First, create a new file in the same directory as the function. These instructions assume that your file will be named template.yml. Once you‘ve created the empty template file, start including resources needed to get your function running. You can begin with defining an S3 bucket to hold your function code:
Once you’ve created the template file and modified it to reflect the resources above, you can deploy your functions from the command line with a single call:
This basic configuration will allow you to deploy your functions once they‘ve been uploaded to the S3 bucket specified in the function definition. You can now build upon this basic set of deployment functionality to automate any aspect of your stack creation. For a fully functional deployment sample, you can clone the excellent quickstart repo from AWS.
Some Tips and Additional Resources
As you work CloudFormation into your Lambda development pipeline, you’re bound to encounter headaches. Here are a few tips to help avoid unnecessary frustration from this immensely helpful AWS blog article on the topic:
Did you know that you can deploy in-line Lambda code? Simply include your (small) Lambda function code as lines appended after the zipfile key.
If you only need to release your functions to a small subset of AWS regions, you can provide a list of regional buckets to populate with your code; simply expand the resource listing when defining your source Lambda zip files.
With a simple name format policy and some custom code, you can create a system that allows you to upload your S3 file once, then publish it to any AWS region that supports AWS Lambda.
In addition to the AWS blog post above, my fellow IOD experts also had a few thoughts on the best ways to achieve serverless deployment zen:
Slobodan Stojanovic gave a detailed overview of the path he took to simplifying his Lambda deployments; it serves as a good case study for transitioning your Lambda deployments into more maintainable patterns.
Once again, the excellent Quickstart repo provided by AWS also offers a useful CloudFormation-driven tool for deploying your AWS Lambda code across multiple regions from a single bucket.
Wrapping Up
AWS Lambda deployments are brittle and prone to error out-of-the-box, requiring you to wade through numerous user interfaces and dialog flows to create your function, associated execution roles, and the resources you need to host your deployable code.
With CloudFormation, you can convert all of this manual configuration into a single template file with the power to describe an entire application stack. CloudFormation replaces the complex and error-prone manual process of deploying Lambda functions with a repeatable, maintainable process that can be maintained alongside your code.
IOD’s expert+editor teams create the kind of content that tech marketing professionals just don’t have the expertise to create.
Personality theories provide a blueprint for understanding why people behave the way they do. In the latest edition of our State of the Developer Nation 22nd Edition – Q1 2022, we incorporated a measure of the widely accepted ‘Big Five’ personality dimensions. We did this in order to better understand the personality traits of software developers. Here, we share some of our findings on developer personalities. Our aim is to discuss how this kind of information can help to support interactions with developers.
Personality measures are a powerful tool for understanding people’s preferences and behaviours. Software teams need diversity not only in terms of skills, experience, and knowledge, but also require a variety of personalities. This will help teams collaborate effectively on complex and challenging projects.
The Ten-Item Personality Inventory
We used the Ten-Item Personality Inventory (TIPI) methodology in order to measure the ‘Big Five’ personality dimensions. These dimensions are: emotional stability, extraversion, openness to experiences, agreeableness, and conscientiousness. The TIPI method is well-suited for situations where short measures are required. The results have been shown to have good alignment with other widely used Big Five measures1. Although more comprehensive and accurate personality measures than TIPI exist, they typically require an entire survey to themselves.
The TIPI method presents respondents with ten pairs of personality traits and asks them to rate how strongly these traits apply to them. Below, we show responses to these items for over 12,000 developers. We find that developers, in general, see themselves as complex and open to new experiences (86% agree or strongly agree that this applies to them), dependable and self-disciplined (79%), calm and emotionally stable (76%), and sympathetic and warm (74%).
Diving deeper into the TIPI data allows us to identify more specific personality types within the general developer population. We collapsed these ten items into five distinct measures, one for each of the Big Five personality dimensions. For example, statements about being ‘sympathetic, warm’ and ‘critical, quarrelsome’ combine to give an overall measure of agreeableness. We then derived a score for each developer on each of the five dimensions. This helped us identify the developer personalities at the polar ends of each dimension, e.g. labelling those who are at the top end of the agreeableness scale as ‘agreeable’ and those at the bottom end as ‘disagreeable’.
Finally, we segmented all developers into a set of distinct personality types. We did this by using the personality labels that they had been assigned as inputs to our segmentation algorithms.
Approximately 8% of all developers differ from the aforementioned group. They showcase a higher level of openness to experiences – often related to intellectual curiosity. These software developers have personality traits that suggest they are likely to investigate new tools and technologies. They are also more likely to stay up to date with the cutting edge of technology.
The Five Developer Personalities
The following charts show the characteristics of five example developer personalities revealed within our data. A well-rounded, ‘balanced’ personality type accounts for 52% of the developer population. These are developers who sit firmly at the centre of each dimension. They are neither introverted nor extroverted, highly agreeable nor disagreeable, emotionally unstable nor lacking emotion, etc.
5% of developers fit a ‘responsible and cooperative’ personality type. These developers score highly in conscientiousness, openness to experiences, and agreeableness in comparison to the majority of developers. Increased conscientiousness often relates to setting long-term goals and planning routes to achieve them, e.g being career-driven. Higher scores for openness to experiences reflects a preference for creativity and flexibility rather than repetition and routine. Our data backs this up. These developers are more receptive to personal development-related vendor resources. For example, 35% engage with seminars, training courses, and workshops compared to 25% of ‘balanced’ developers. Their high scores for agreeableness also correlate with greater engagement with community offerings. For example 23% attend meetup events compared with 17% of ‘balanced’ developers.
5% of developers conform to an ‘achievement-driven and emotionally stable’ profile. As with the previous personality type, they are conscientious and open to experiences. However, they score much higher in terms of emotional stability but slightly lower in terms of agreeableness. Developers who score high in emotional stability react less emotionally. For example they favour data over opinions. Lower agreeableness can be a useful trait for making objective decisions, free from the obligation of pleasing others.
We also find a segment of developers with an ‘introverted and unreliable’ profile. They indicate that they are less involved in social activities, disorganised, closed to new experiences, and less agreeable than other developers. Fortunately, these developers, who are likely hard to reach and engage in new activities and communities, are a very small minority, at 2% of all developers.
Developer Personalities, Roles and Content Preferences
Finally, we show how the characteristics of these developer personalities vary, in terms of both associations with developer roles and the kinds of information and content that they consume. Developers in the ‘balanced’ profile are most likely to have ‘programmer/ developer’ job titles. However, those who fit the ‘responsible and cooperative’ profile are disproportionately more likely to occupy creative (e.g UX designer) roles. This aligns with their increased creativity/openness, and senior CIO/CTO/IT manager positions, reflecting their self-discipline and achievement striving.
Those who are ‘achievement-driven and emotionally stable’ are less likely than other personality types to have ‘programmer/developer’ job titles, but disproportionately more likely to be data scientists, machine learning (ML) developers, or data engineers. They tend to deal mainly in facts and data rather than opinions and emotions. Those in the ‘introverted and unreliable’ profile are more likely to have test/QA engineer and system administrator job titles than those in other personality types.
When it comes to where developers go to find information and stay up to date, perhaps unsurprisingly, the ‘introverted and unreliable’ personality type uses the fewest information sources overall, affirming that they are a difficult group to engage via community-focussed events and groups. However, their use of social media is in line with other personality types, suggesting that this may be a suitable channel for catching the attention of this hard-to-reach group.
Both of the high-conscientiousness and high-openness personality types use the widest range of information sources overall, however, those who are more cooperative are considerably more likely to turn to social media for information about software development (53% of the ‘responsible and cooperative’ type vs. 44% of the ‘achievement-driven and emotionally stable’ type).
‘Intellectually curious’ developers are the most likely to make use of official vendor resources and open source communities. Hence, the audience that vendors reach via these resources may be slightly more keen to experience new products and offerings, than the typical ‘balanced’ developer.
What’s Next with Developer Personalities
We just began to scratch the surface of developers’ personality profiles. The personality types we have shown are indicative of just a few of the differences that exist among developers. By capturing this kind of data, we’ve opened the door for more extensive profiling and persona building, along with a deeper analysis of how the many other developer behaviours and preferences that we track align with personality traits. If you’re interested in learning more about developer personalities and how this can help you to reach out to developers, then we’re very excited to see how our data can support you.
In this article, we’ll be learning about the basics of the data storage mechanism for git.
The most fundamental term we know regarding git and data storage is repositories. Let’s first understand what a git repository is and where it stands in terms of data storage in git.
Are you ready to influence the tech landscape? Take part in the Developer Nation Survey and be a catalyst for change. Your thoughts matter, and you could be the lucky recipient of our weekly swag and prizes! Start Here
Repositories
A git repository can be seen as a database containing all the information needed to retain and manage the revisions and history of a project. In git, repositories are used to retain a complete copy of the entire project throughout its lifetime.
Git maintains a set of configuration values within each repository such as the repository user’s name and email address. Unlike the file data or other repository metadata, configuration settings are not propagated from one repository to another during a clone, or fork, or any other duplication operation. Instead of this, git manages and stores configuration settings on a per-site, per-user, and per-repository basis.
Inside a git repository, there are two data structures – the object store and the index. All of this repository data is stored at the root of your working directory inside a hidden folder named .git. You can read more about what’s inside your .git folder here.
As part of the system that allows a fully distributed VCS, the object store is intended to be effectively replicated during a cloning process. The index is temporary data that is private to a repository and may be produced or edited as needed.
Let’s discuss object storage and index in further depth in the next section.
Git Object Types
Object store lies at the heart of the git’s data storage mechanism. It contains your original data files, all the log messages, author information, and other information required to rebuild any version or branch of the project.
Git places the following 4 types of objects in its object store which form the foundation of git’s higher-level data structures:
blobs
trees
commits
tags
Let’s look a bit more about these object types:
Blobs
A blob represents each version of a file. “Blob” is an abbreviation for “binary big object,” a phrase used in computers to refer to a variable or file that may contain any data and whose underlying structure is disregarded by the application.
A blob is considered opaque it contains the data of a file but no metadata or even the file’s name.
Trees
A tree object represents a single level of directory data. It saves blob IDs, pathnames, and some metadata for all files in a directory. It may also recursively reference other (sub)tree objects, allowing it to construct a whole hierarchy of files and subdirectories.
Commits
Each change made into the repository is represented by a commit object, which contains metadata such as the author, commit date, and log message.
Each commit links to a tree object that records the state of the repository at the moment the commit was executed in a single full snapshot. The initial commit, also known as the root commit, has no parents and the following most of the commits have single parents.
A Directed Acyclic Graph is used to arrange commits. For those who missed it in Data Structures, it simply implies that commits “flow” in one way. This is usually just the trail of history for your repository, which might be very basic or rather complicated if you have branches.
Tags
A tag object gives a given object, generally a commit, an arbitrary but presumably human-readable name such as Ver-1.0-Alpha.
All of the information in the object store evolves and changes over time, monitoring and modeling your project’s updates, additions, and deletions. Git compresses and saves items in pack files, which are also stored in the object store, to make better use of disc space and network traffic.
Index
The index is a transient and dynamic binary file that describes the whole repository’s directory structure. More specifically, the index captures a version of the general structure of the project at some point in time. The state of the project might be represented by a commit and a tree at any point in its history, or it could be a future state toward which you are actively building.
One of the primary characteristics of Git is the ability to change the contents of the index in logical, well-defined phases. The indicator distinguishes between gradual development stages and committal of such improvements.
How does git monitor object history?
The Git object store is organized and implemented as a storage system with content addresses. Specifically, each item in the object store has a unique name that is generated by applying SHA1 to the object’s contents, returning a SHA1 hash value.
Because the whole contents of an object contribute to the hash value, and because the hash value is thought to be functionally unique to that specific content, the SHA1 hash is a suitable index or identifier for that item in the object database. Any little modification to a file causes the SHA1 hash to change, resulting in the new version of the file being indexed separately.
For monitoring history, Git keeps only the contents of the file, not the differences between separate files for each modification. The contents are then referenced by a 40-character SHA1 hash of the contents, which ensures that it is almost certainly unique.
The fact that the SHA1 hash algorithm always computes the same ID for identical material, regardless of where that content resides, is a significant feature. In other words, the same file content in multiple folders or even on separate machines produces the same SHA1 hash ID. As a result, a file’s SHA1 hash ID is a globally unique identifier.
Every object has an SHA, whether it’s a commit, tree, or blob, so get to know them. Fortunately, they are easily identified by the first seven characters, which are generally enough to identify the entire string.
One fantastic benefit of saving only the content is that if you have two or more copies of the same file in your repository, Git will only save one internally.
Conclusion
In this article, we learned about the two primary data structures used by git to enable data storage, management, and tracking history. We also discussed the 4 types of object types and the different roles played by them in git’s data storage mechanism.
This was all for this article, I hope you find it helpful. These are the fundamental components of Git as we know it today and use on a regular basis. We’ll be learning more about these Git internal concepts in the upcoming articles. Keep reading. In case you want to connect with me, follow the links below:
Choosing a programming language can be complicated as many aspects need consideration. You might wish it was as easy as choosing between various flavors of ice cream or pizza. Ask any developer or technical manager to understand what drives popular choices in the tech world. In this article, you can learn what drives a choice of programming languages and the data-driven decisions developers should take to safeguard their careers while ensuring success in the projects they deliver.
Technology changes rapidly in today’s digital race, and the chosen language must get future potential to remain in use with strong developer communities, or else organizations can face maintenance and integration issues. Even young developers are keen to know which languages have excellent career potential, so they invest their time wisely.
Young developers may make the mistake of choosing a programming language because it’s trendy and cool. As a young developer, you can avoid these mistakes by referring to various tech forums and authentic sources like Slashdata’s – 22nd edition of The State of the Developer Nation (Q1 2022) that offer insights into popular programming languages and their growth trends.
Choosing a programming language
The choice of a programming language gets intertwined between your career aspirations and work experience. You learn a programming language and need to work on projects to gain relevant industry experience. So as a developer, you need to have a holistic approach to choosing a suitable language.
Choosing a programming language depends on various factors, and you should know all the components to get a better view and then make a choice. A good selection of programming languages will lead to spending less time on scaling, maintenance, and other aspects like security in projects.
Here are some typical questions you must ask when choosing a programming language for a project.
Does the programming language have proper community ecosystem support? Is it going to work over the long term? Is vendor support available?
What is the type of environment for the project – web solution, mobile, cross-platform, etc.?
Are there any infrastructure considerations like new hardware or particular deployment needs?
What do the clients prefer?
Are there any specific requirements for the programming language’s libraries, tools, or features?
Are experienced developers available for the programming language?
Are there any performance considerations, and can the language accommodate this performance?
Is there a security consideration or requirement for any third-party tool?
It would help if you remembered that irrespective of the chosen programming language, you can write good or bad code with any language. Besides the typical questions above, it’s advisable to consider a few critical factors in-depth before choosing a programming language. In programming, adherence to widely accepted design principles and philosophies is essential.
Some critical considerations driving the choice of a language include the following:
1. Type of application
The type of application varies from complicated embedded firmware to web and mobile. Common programming languages like Java, Python, JavaScript and C# can build different types of applications on various platforms. There are also situations where specific languages work better. With the rise in mobile apps, for example, you would choose Java for building a native Android app or a C and C++ combination for an embedded firmware project.
2. Complexity of applications
Identifying the application’s size and complexity helps determine the choice of programming language. The smaller and simple applications like marketing websites or webforms can use content management systems (CMS) like WordPress that may need minimal programing. On the other hand, complex applications like e-commerce websites or enterprise applications or emerging technology applications like IoT devices or AI-based applications may require Java or C#. As a technical manager, you can be an expert in gauging complexity with various experiences.
3. Organization culture
The choice of Open source technologies vs. proprietary software tends to rest with the organization’s culture and a direction often set by management. All programming languages have a trade-off, and some companies may choose one that is scalable, while others may pick one that has a shorter learning curve and is easy for the developers. Whatever the culture, the priority should be on choosing a language that optimally addresses the project needs. You can easily understand an organization’s choice once you start working on their technology stack.
4. Time to market:
Businesses rely on getting their product to the market early for competitive gains. Choosing new programming technologies and languages is better for a project with longer timelines. You can complete your project faster by leveraging the developers’ existing skills. For example, if you already have an AWS-based cloud environment and relevant team expertise, it will be quicker to work on it than move to another technology environment.
5. Maintainability
Technology stacks have their library ecosystems and vendor support. Choose a programming language with regular update releases that will stay current for some time. Maintaining the codebase is essential, and maintenance costs depend on the availability of developers. For example, as per today’s trends hiring Java, C#, Python, or PHP developers is easy and cost-effective. Organizations can make a data-driven decision by looking at the size of programming language communities from various industry reports from Slashdata.
6. Scalability, performance, and security:
The performance of the application depends on your choice of programming languages. It becomes essential when the development environment has limitations on scaling. Some popular tech stacks with great scalability include Ruby on Rails (RoR), .NET, Java Spring, LAMP, and MEAN.
It would be best if you protected applications from cyber threats. Following the security guidelines are crucial before choosing any programming language for your application. For example, a financial application needs PCI compliance, while healthcare-related applications need HIPAA compliance. Your choice of programming languages must be able to deliver application compliance.
Insights – Slashdata – 22nd edition of The State of the Developer Nation (Q1 2022)
You know the factors that drive the choice of programming languages. Let us look at findings from the Slashdata – 22nd edition of The State of the Developer Nation (Q1 2022). It offers exciting statistics that can help you as a developer know if your skills are up to date or need an upgrade.
JavaScript remains the most prominent language community, with close to 17.5M developers worldwide using it.
Python has remained the second most widely adopted language behind JavaScript, with the gap between the two largest communities gradually closing. Python now counts 15.7M users after adding 3.3M net new developers in the past six months alone.
The rise of data science and machine learning (ML) is an apparent factor in Python’s growing popularity. About 70% of ML developers and data scientists report using Python versus only 17% using R.
Java is one of the most critical general-purpose languages and the cornerstone of the Android app ecosystem. Although it has been around for over two decades, it is experiencing strong and steady growth. Nearly 5M developers have joined the Java community since 2021.
Data shows that Java’s growth gets fueled by the usual suspects, i.e., backend and mobile development, and its rising adoption in AR/VR projects.
Wrapping up
We hope you have more clarity and data-driven insights in choosing programming languages for your career and projects. We encourage you to regularly read the whole SlashData – 22nd edition of The State of the Developer Nation (Q1 2022) report and stay updated on trending technologies.
Crypto, Blockchain and Web3 are buzzwords these days and while you might already hold some Bitcoin on Coinbase or Binance, you might also be wondering how you can move your career into this new industry as a developer.
Good blockchain developers are highly sought after and becoming an expert in these new technologies can bring you an exceptionally high income as well as job security.
It’s easy to google “How to become a blockchain developer” to find out what technical skills you will need and what programming languages you will have to learn. You will find lots of helpful information e.g. here and here.
According to the latest State of the Developer Nation Report, blockchain applications, cryptocurrencies, and NFTs have the highest share of developers learning about them.
More specifically with regards to Cryptocurrencies, out of a sample of 13,939 developers, 50% stated they are interested in them, 34% said they are learning about them while 16 % have already adopted the technology.
But what actually is Crypto, Blockchain and Web3? And – once you have the skills – how are you going to get your foot in the door and create long-term success?
Ecosystem Education
If you are a complete newbie, I’d suggest educating yourself on the origins and philosophy of bitcoin and blockchain first, as well as the evolution of Web3. There are some great free courses that will give you a solid foundation and might help you find a niche to focus your efforts on.
UnitMasters.org for example is an engaging 6-week course that will give you a good high-level overview of the Web3 ecosystem. It is very welcoming to participants from all walks of life and underrepresented backgrounds.
The free MOOC on Digital Currencies by the University of Nicosia, which is taught by prominent bitcoin educator Andreas Antonopoulos, is a great place to start if you really want to understand how bitcoin works and why it is here.
Crypto Job Boards
There are a number of job boards dedicated to Web3, but simply submitting your CV has never been the best way to go about this, in my opinion. Nevertheless, it’s helpful to know about them, so here are a few you can check out:
The best positions are often filled before they make it to a job board, since candidates are being hired from within the network of the recruiter or the organization hiring. That’s why it is important to connect with others in the space. If the term “networking” makes you cringe or sounds like a chore to you, here are some easy ways to go about that:
Attend crypto meet-ups or blockchain conferences to learn about all the things that are being built in this space. You’ll be amazed what some teams are creating out there and you will surely find something that excites you, or sparks your own ideas.
Join the online communities of the projects that you are most interested in. Most of them have a Discord community, which you can find on their websites. Start chatting with other developers in there who may be looking for team members and look out for vacancies in their announcement channels.
Start using some DApps (Decentralized Applications) – whether it’s a simple wallet to send and receive cryptocurrency or blogging platforms like Hive that allow you to earn cryptocurrency for your content. If you’re a gamer, check out games like Splinterlands or Axie Infinity. It’s easiest to start with something you already know.
No matter what your background is, begin using Web3 apps so you gain personal experience as a user. This will help you learn about their challenges or short-comings and you can begin thinking about solutions for them – whether it is UX design or their token economy. You could begin contributing to their improvements, or you could join (or create) a team that will build something better.
Many people get hired by companies because they have proven their knowledge, engagement and contribution in their communities already.
Web3 projects don’t hire staff, they recruit members.
This goes not only for other stakeholders like customers, users, block producers and investors. Crypto projects are win-win-win communities. All stakeholders are equally important in their contributions to help the project succeed.
4. Join Hackathons and coding bootcamps. Stay in touch with the people you meet there. They might all end up in different projects, so this is a great way to build your professional network.
5.Start creating content! Whether it’s your own blog, a Hive account, or your Github account. Begin creating a public track record of your thoughts or technical contributions to the space.
“Don’t trust. Verify.” This famous crypto slogan applies not only to the blockchain but also to you. Creating a verifiable track record is worth so much more than a fancy CV. Your track record will speak for itself and send projects your way, rather than you having to look for them. Project teams don’t care about your CV, they care about your proven experience and contributions to the industry.
6.Join a DAO and see how you can begin contributing. DAO’s – Decentralised Autonomous Organisations – are an essential part of the Web3 space and might just become the way we will all work and organize ourselves in the future. You can submit proposals and get your contributions funded by the DAO’s treasury, if your fellow DAO members vote for it. Check out LobsterDAO or HerDAO (for womxn developers)to get started.
7. Check out Gitcoin where projects post small tasks that you can earn cryptocurrency for. It will help you build a track record, too.
Community Is The New Currency
Everything in the crypto and Web3 space revolves around communities. There is very little of the top down structures you may be used to. The value of crypto tokens comes from their community of developers and users, and you will also end up choosing your project by the community it already has, or the potential it has to create one. (Are they building something that you think will be adopted by a large number of people? Is it going to make a difference to anyone?)
Make Everyone Want To Work With You
You may be highly intelligent, but intellectual intelligence is not the only ingredient for success. You can be a genius, but it will be of little use if nobody likes working with you.
Emotional intelligence is a highly important part in communities. Web3 is all about “we” rather than “me”. People like to surround themselves with people they like and get along with. Even though everyone can code from their bedroom or a hammock on a remote island these days – be kind, be agreeable, be generous in your communication with others. Online and offline. Be a team player. Be someone that CEO’s, investors and HR or customer service staff enjoy working with.
Making interpersonal communication skills just as important as your technical skills will help you become a highly valued and sought-after contributor and create lasting success!
Already a developer interested in Blockchain? Take the Developer Nation survey, share your views on new technologies, tools or platforms for 2023 and shape the future of the Developer Ecosystem. You will get a virtual goody bag with free resources, plus a chance to win an iPhone 13, a Samsung Galaxy S22, Amazon vouchers and more. Start here
Anja Schuetz is an Operations Management Consultant who has worked for several crypto wallets and blockchain projects. She also mentors first-time crypto investors and helps newcomers move their careers into Web3. Learn more about Anja at https://linktr.ee/consciouscrypto
Developer Nation is continuously trying to bring high quality articles for your career path and your company/organisation among insights, tips, interviews and more from the developer ecosystem. This time we have the honour to host an article by IOD about roles, career growth and leadership, focusing on Cloud, SRE, and DevOps Experts.
This article was contributed by IOD. IOD is seeking new tech bloggers. If you are a top notch tech expert or a writer, join IOD’s talent network and share your expertise!
Today, every company is leveraging technology to innovate, streamline operations, and create value for their customers. Regarding software engineering, developers have a natural and prominent role in creating new capabilities and opportunities, but that cannot happen without a greater support infrastructure. Cloud, SRE (site reliability engineering), and DevOps engineers are central to value delivery and business continuity. It is vital for engineering managers to understand how they can become mentors in order to coach and upskill these experts to both enable their career growth and increase business value.
Distinctions Between Expert Roles
Modern software development teams work in a DevOps way, by bringing people with different competencies together and enabling a faster, higher-quality value delivery and development lifecycle.
Writing the application business logic is only part of the engineering equation needed to deliver customer value. The other part, operations, includes many tasks that are mostly driven by Cloud, SRE, and DevOps experts. Good examples of those tasks are designing scalable and reliable systems, ensuring that code can be tested and deployed using continuous integration and delivery pipelines, monitoring system health, and implementing security and compliance guidelines.
Personally, I dislike the title “DevOps Engineer,” because DevOps is applicable to the entire engineering team and is a more abstract concept. SRE, on the other hand, is a concrete implementation of the DevOps philosophy—experts in an SRE role bridge the gap between developers and operations. A DevOps engineer (what I prefer to call the “automation/cloud specialist”) differs from an SRE, as they only focus on systems operations.
There are some natural derivations in lateral roles that come from further specialisation in certain technology areas such as DevSecOps engineer, chaos engineer, or cloud and solution architects at more senior levels.
SRE and cloud specialists are crucial to the success of the product or service. Yet, they are too often disconnected from the business reality; this is where coaching and mentoring makes all the difference.
Mentoring Is Vital to Career Growth
Engineering managers have the lead role in mentoring and coaching these experts: guiding, providing feedback, showing different career possibilities, and building bridges within the rest of the organisation. Engineering managers can act as human routers to make the connection between experts and business stakeholders, ensuring experts get first-hand knowledge and visibility on the value and end-user experience of the product(s) and service(s) that they work on.
Similarly, managers can then demonstrate to stakeholders the positive business impact of these experts’ actions. Does the solution have a great reliability track record and always meet the agreed SLAs? Tell them about it! What would it take to enable solution architecture to scale ten-fold and be available in other geographical locations to support new business cases? Great conversation starter!
How to Make It Happen
Unfortunately, business stakeholders usually only connect with these experts when something goes wrong (e.g., a system failure), and need to understand what happened and why. Engineering managers can change this pattern and create a new paradigm.
Here are a few things managers can do to establish this paradigm and foster its culture:
Translate business and industry-specific jargon into technical concepts, examples, and terminology that experts can relate to.
Help experts develop the necessary non-technical skills to communicate effectively, and translate complex engineering scenarios into simple, relatable terms and ideas with business impact.
Facilitate sessions where experts can present and showcase potential opportunities that new cloud and data technologies can unlock in the organisation, generating new business models or streamlining existing operations and processes.
Create and explore opportunities for experts to shadow and connect directly with colleagues in different roles across the organisation, such as working alongside a customer support representative or joining a sales meeting.
This enables constructive cooperation across competencies, breaking silos while helping these experts grow and gain a better understanding of their impact in the organisation.
Upskilling, Community, and Thought Leadership
There is no substitute for hands-on learning, and engineering managers have a unique role in creating those opportunities. It’s important to maintain a continuous dialog to understand the expert’s career goals and interests, while simultaneously facilitating situations that enable them to gain new hands-on experience.
Simple and small steps, such as inviting them to a steering meeting, participating in a technical brainstorming workshop, or joining a new, exciting project (even if in a minor role) can make a huge difference and impact. Venturing out of one’s comfort zone is always an opportunity to grow and learn.
Further, hands-on experience should always be accompanied by other learning and input, such as insights from other experts, industry certifications, or non-technical skills development.
Certifications and Digital Content
Consuming digital content—articles, videos, whitepapers—and pursuing industry certifications—such as those offered by AWS, Microsoft, Google, and the Cloud Native Computing Foundation—are both excellent practices for validating existing knowledge and discovering new services, expert insights, and best practices.
Each of these organisations offer certifications that go from the fundamentals to complex solution architecture scenarios, focusing on areas such as security, networking, and data engineering. When combined with hands-on experience outside of typical work tasks, content-learning and certifications provide natural upskilling and specialisation pathways that stay with the expert even when changing jobs or companies.
There are also plenty of advantages to an organisation that has certified experts. It nudges the organisation toward good practices and ways of working, while enabling the company to level up their cloud partnership status and showcase their expertise to customers.
Technology Communities
In organisations, from SMBs to larger corporations, there is a natural tendency for individuals to become siloed in their team and/or business unit. Cloud, SRE, and DevOps are domains transversal to all development teams and organisational structures. Fostering an internal technology community where these experts can regularly meet increases alignment and promotes a healthy exchange of ideas. Moreover, it enables these experts to drive the technology governance and foster a culture of engineering excellence across the organisation.
Similarly, external communities and events are also a great way to gain new insights and fresh perspectives. DevOpsDays, ServerlessDays, as well as AWS and Azure Community Days and Meetups, to name a few, are fantastic options to learn and meet like-minded people. With practically all events now fully virtual and often free to attend, this is something that should be highly encouraged and promoted in your organisation.
Sharing Experiences and Thought Leadership
Engineers, especially less experienced ones, might be intimidated at the prospect of sharing their insight and experiences in technical articles or public speaking engagements. Regardless of the level of the content, whether beginner’s guides or more advanced deep dives, there is considerable value in creating content and sharing knowledge. Entry-level content from a Cloud, SRE, or DevOps expert can offer tremendous value to a developer or business stakeholder not familiar with the topic, and it can help bridge gaps between different competencies.
From a career growth perspective, an expert that invests time and effort in thought leadership activities—including written content and speaking engagements—is more likely to accelerate their professional growth and seniority. This is not first because of the positive visibility that those activities bring to themselves and their organisation (that helps!), but rather, it enables the expert to radically improve and develop valuable communication skills. Simply, with practice comes change; the more we work to translate and express complex thoughts and ideas into written and verbal content, the less subject we are to our own silos.
Conclusion
Coaching and upskilling Cloud, SRE, and DevOps experts reveals new possibilities for impacting how an organisation operates and delivers. With these experts, it’s critical that direct managers and senior leadership start seeing and treating them as essential value creators, not cost centres.
When mentoring these experts, help them understand their potential career paths and growth, and highlight the value they create and the impact they make in the organisation. Most importantly, be transparent, provide constructive feedback, and foster a psychologically safe environment that encourages them to venture beyond their comfort zone and try bringing in new ideas.