
The choice of programming language matters deeply to developers because they want to keep their skills up-to-date and marketable. Languages are a beloved subject of debate and the kernels of some of the strongest developer communities. They matter to toolmakers, too, because they want to make sure they provide the most useful SDKs.

It can be challenging to accurately assess how widely a programming language is used. The indices available from sources like Tiobe, Redmonk, Github’s State of the Octoverse, and Stack Overflow’s annual survey are great but offer mostly relative comparisons between languages, providing no sense for the absolute size of each community. These may also be biased geographically or skewed toward certain fields of software development or open-source developers.
The estimates presented here look at software developers using each programming language globally and across all kinds of programmers. They are based on two pieces of data. First is SlashData’s independent estimate of the global number of software developers, which was published for the first time in 2017. According to it, as of Q1 2023, there are 35.6 million active software developers worldwide. Second is the large-scale, low-bias Developer Nation Global survey which reaches tens of thousands of developers every six months. In these surveys, devleopers are consistently asked about their use of programming languages across 13 areas of development. This gives a rich and reliable source of information about who uses each language and in which context.
JavaScript remains the most widely used language.
For the 12th survey in a row, JavaScript continues to take the top spot for programming languages, with 20M active developers worldwide. Notably, JavaScript is still experiencing growth, with a further 2.6M developers joining the community in the last 12 months. JavaScript’s lead is unlikely to be challenged in the near future, as its community has almost 3M more developers than the next closest languages. Moreover, JavaScript’s popularity extends across all software sectors, with at least 20% of developers using it in their projects.
“Close to eight million developers joined the Java community in the last two years.”
In 2020, Python unseated Java as the second most popular programming language, but in Q1 2023, Java returned to just matching Python, with both languages now counting just over 17M developers. Java is one of the most important general-purpose languages, and although it is over two decades old, it has seen incredible growth over the last two years, gaining close to 8M users. This corresponds to the highest growth in absolute terms across all languages. Java’s growth is not only supported by traditional sectors such as cloud and mobile but also by its rising adoption among AR/VR developers, in part due to Android’s popularity as an AR/VR platform.
Despite Java catching up, Python keeps adding new developers. However, in the last 12 months, only 1.3M developers joined the Python community, compared to the massive 5.6M developers who joined between Q1 2021 and Q1 2022. A major driver of Python’s growth was the rise of data science and machine learning, where 70% of developers involved were using Python in Q1 2022. However, this has decreased to 60% in Q1 2023, with other languages, such as Rust, Java, and Mathematica, receiving small increases and likely reducing Python’s growth.
The group of major, well-established languages is completed with C/C++ (13.3M), C# (11.2M), and PHP (8.8M). PHP has seen the second-slowest growth rate over the last 12 months, growing just 11% and adding 0.9M developers to its community. PHP is a common choice for backend and web developers but has seen decreasing popularity.
PHP was used by almost 30% of all developers in Q3 2020 but by 25% of all developers in Q1 2023. This decrease in popularity is particularly apparent amongst web developers, for whom it has gone from the second most popular language in Q3 2021 (34%) to the fourth most popular language (25%) in Q1 2023, behind JavaScript, Python, and Java. Despite PHP 8 addressing many of the concerns developers had expressed about PHP, perceptions of it being insecure or outdated may persist.
C and C++ are core languages in embedded and IoT projects, for both on-device and application-level coding, but also in desktop development, a sector that accounts for almost 45% of all developers. On the other hand, C# has maintained its position as one of the most popular languages for games and desktop applications. Overall, C/C++ added 2.3M net new developers in the last year, while C# added 1.4M over the same period.
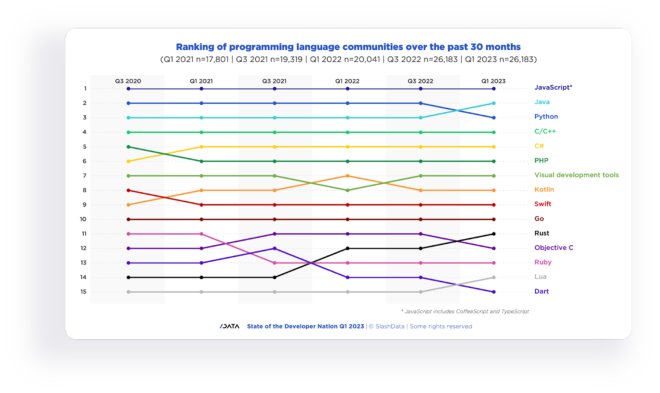
Kotlin’s growth is beginning to slow
In previous editions of this report, Kotlin and Rust were identified as two of the fastest-growing language communities. If Kotlin’s growth continues, it will soon overtake PHP and join the ranks of the most popular languages. Kotlin’s growth has been largely attributed to Google’s decision in 2019 to make it the preferred language for Android development. It is currently used by 19% of mobile developers and is the third most popular language in the space. However, Kotlin may be showing signs of slowing its exceptional growth. Kotlin now has a community of more than 5.3M developers and has added more than 2.5M developers in the last two years. However, in the last year, there has only been an increase of 0.5M developers. Kotlin’s explosive growth may have resulted from a high demand for developers with Kotlin experience to fill a market need that may be approaching a level of market saturation. Despite Google’s preference for Kotlin, the inertia of Java means that it is still the most popular language for mobile development and still experiences immense growth.
“Rust has more than tripled the size of its community in the past two years”
Rust has more than tripled the size of its community over the past two years and currently has 3.7M users, of which 0.6M joined in the last six months alone. Rust has overtaken Objective C in the last six months and is the 11th most popular language in our survey. Rust has seen increased adoption in IoT, games, and desktop development, where it is desired for its potential to build fast and scalable applications. Rust was designed to handle high levels of concurrency and parallelism. Thus it can handle increasing amounts of work or data without sacrificing performance. Furthermore, Rust has built a loyal community of developers who care about memory safety and security.
Swift currently counts 5.1M developers, adding more than 1.6M net new developers over the past year. This growth continues to stem from Apple making Swift the default programming language across the Apple ecosystem, which has the effect of phasing out the use of Objective C. Despite this, Objective C has also shown strong growth, adding 1.0M developers in the last year alone, resulting in a community of 3.4M developers. This is primarily through its use among IoT developers, who are increasingly turning to it for their on-device code, as well as a growing number of AR/VR developers. Nonetheless, Objective C has fallen behind Rust, whose more modern approach may be more appealing to developers.
Go and Ruby represent two of the smaller language communities that are important in backend development, but Go has seen substantially more growth over the last two years. Go’s developer community has more than doubled in the last two years, adding 2.3M new developers to its population, which stands at 4.7M developers. Similarly, Ruby has added 1.0M users to its community of 3.0M developers, showing impressive growth but trailing further behind Go.
“Lua has added almost 1M developers to its community in the past year”
In the past six months, Lua has overtaken Dart to become the 14th most popular programming language. Lua has shown massive growth over the past year, going from 1.4M developers in Q1 2022 to 2.3M in Q3 2023. Lua is an alternative scripting solution for low-level languages, such as C and C++, and has seen more developers in IoT, games, and AR/VR picking it up. This could mark the beginning of Lua’s momentum and see it become increasingly popular, especially as the IoT and AR/VR spaces continue to grow. Dart has seen steady but slow growth over the past two years, predominantly due to the Flutter framework in mobile development filling a useful niche. However, with 13% of mobile developers currently working in Dart, a decrease from 15% in Q1 2022 may see Dart’s growth remain low, and its place within mobile development remain a minority language.















